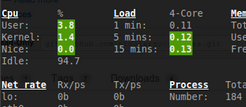
Une petit billet « quick and dirty » entre deux lignes de code sur la prochaine version de Glances qui s’annonce dantesque, pour installer Krita, une alternative pas si improbable à Photoshop, sur votre machine Ubuntu Gnome ou Unity.
La preuve ? L’université de Paris 8 vient juste de migrer de Photoshop vers Krita pour sa section Art et technologie de l’image
J’ai un peu galérer avant d’avoir un logiciel complètement utilisable sur une machine non nativement KDE (comme mon Ubuntu Gnome Edition). Donc voici les commandes à saisir:
Tous ceux qui se sont intéressés à l’optimisation du référence de leur site dans la sainte base de donnée de Google le savent bien, le temps de chargement des pages est un des facteurs clé pour en établir le classement. Google ne s’en cache plus depuis longtemps et propose toute une batterie d’outil pour identifier et optimiser la vitesse d’affichage de votre site.
Nous allons dans ce billet nous intéresser à l’optimisation de la couche basse de votre site, c’est à dire sans modification du contenu des pages, en mettant en place le module PageSpeed sur le serveur Web NGinx. J’ai utilisé un serveur sous Debian mais vous pouvez appliquer ceci, moyennant quelques adaptations, sur d’autres systèmes d’exploitations.
PageSpeed Module ? Kesako ?
Google a regroupé sous l’acronyme PageSpeed, un ensemble d’outils pour aider les Webmasters à optimiser leurs sites. Un des ces outil est nommé PageSpeed Module. C’est un module optionnel disponible pour les serveurs Web Apache et NGinx.
Une fois installé et configuré, ce module va, de manière dynamique et transparente, effectuer un ensemble d’optimisations lors de la mise à disposition de vos pages à vos utilisateurs. Chaque optimisation est mise en place sous la forme d’un filtre qui vont par exemple changer dynamiquement le contenu HTML de vos pages, trouver des emplacements de javascripts plus rapide ou bien optimiser les images. Comme, nous le verrons plus loin, la liste des filtres est bien sûr paramétrable au niveau des fichiers de configuration de NGinx.
Trêve de long discours, passons maintenant à l’installation et à la configuration de PageSpeed Module avec un serveur NGinx.
Installation de NGinx + PageSpeed Module
Vous savez tout le bien que je pense du serveur Web NGinx. J’ai donc profité de ce billet pour mettre à jour mon script d’installation automatique de NGinx afin d’y intégrer le module PageSpeed. Ainsi pour les plus pressés d’entre-vous, il suffit de télécharge ce script et de le lancer à partir d’un compte administrateur pour avoir une configuration NGinx + PageSpeed.
Pour les autres, les plus curieux, nous allons détailler l’installation dans la suite de ce paragraphe.
On commence donc par se créer un répertoire de travail:
mkdir ~/install-nginx-pagespeed
cd ~/install-nginx-pagespeed/
unzip release-1.7.30.3-beta.zip
cd ngx_pagespeed-release-1.7.30.3-beta/
tar zxvf ../1.7.30.3.tar.gz
cd ..
A ce stade, le répertoire ngx_pagespeed-release-1.7.30.3-beta contient donc le module PageSpeed prêt à être intégré aux sources de NGinx.
On récupère donc les sources de ce dernier:
wget http://nginx.org/download/nginx-1.4.4.tar.gz
On décompresse puis on installe:
tar zxvf nginx-1.4.4.tar.gz
cd nginx-1.4.4/
./configure --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --pid-path=/var/run/nginx.pid --lock-path=/var/lock/nginx.lock --http-log-path=/var/log/nginx/access.log --with-http_dav_module --http-client-body-temp-path=/var/lib/nginx/body --with-http_ssl_module --http-proxy-temp-path=/var/lib/nginx/proxy --with-http_stub_status_module --http-fastcgi-temp-path=/var/lib/nginx/fastcgi --with-debug --with-http_flv_module --with-http_realip_module --with-http_mp4_module --add-module=../ngx_pagespeed-release-1.7.30.3-beta
make
Enfin on installe la nouvelle version de NGinx contenant le module PageSpeed sur son système (attention cela va écraser votre installation existante mais pas les fichiers de configurations).
sudo make install
On relance NGinx pour prendre en compte la nouvelle installation.
sudo service nginx restart
On a donc un beau NGinx avec le module PageSpeed disponible. Par défaut, ce module n’est pas activé. Il faut donc passer à l’étape suivant: la configuration du module.
Configuration du module PageSpeed pour NGinx
C’est assez simple car tout est localisé dans la section server (ou http dans la cas d’une mutualisation avec plusieurs hôtes virtuels) des fichiers de configuration de NGinx. On commence donc par identifier cette section puis d’y ajouter les lignes suivantes pour activer le module PageSpeed en mode « pass through » (ce mode permet de choisir de manière exhaustive les filtres à appliquer):
server {
...
# PageSpeed
# enable ngx_pagespeed
pagespeed on;
pagespeed FileCachePath /var/ngx_pagespeed_cache;
# Ensure requests for pagespeed optimized resources go to the pagespeed handler
# and no extraneous headers get set.
location ~ "\.pagespeed\.([a-z]\.)?[a-z]{2}\.[^.]{10}\.[^.]+" {
add_header "" "";
}
location ~ "^/ngx_pagespeed_static/" { }
location ~ "^/ngx_pagespeed_beacon$" { }
location /ngx_pagespeed_statistics { allow 127.0.0.1; deny all; }
location /ngx_pagespeed_global_statistics { allow 127.0.0.1; deny all; }
location /ngx_pagespeed_message { allow 127.0.0.1; deny all; }
...
}
Ces lignes permettent:
d’activer pagespeed (pagespeed on)
de configurer le répertoire utiliser par PageSpeed pour cacher ses informations (FileCachePath)
de s’assurer que les requêtes vers PageSpeed ne sont pas perturbées (location)
Pour le cache on utilise le répertoire /var/ngx_pagespeed_cache qu’il faut créer et configurer au niveau des droits pour que NGinx puisse y accéder (dans mon cas, le processus NGinx est lancé avec l’utilisateur www-data).
Ensuite à la suite des autres lignes de la section server (ou http) on active les filtres souhaités. Voici un exemple des filtres que j’utilise sur mon serveur hébergeant ce blog:
server {
...
# enable collapse whitespace filter
pagespeed EnableFilters collapse_whitespace;
# enable JavaScript library offload
pagespeed EnableFilters canonicalize_javascript_libraries;
# combine multiple CSS files into one
pagespeed EnableFilters combine_css;
# combine multiple JavaScript files into one
pagespeed EnableFilters combine_javascript;
# remove tags with default attributes
pagespeed EnableFilters elide_attributes;
# improve resource cacheability
pagespeed EnableFilters extend_cache;
# flatten CSS files by replacing @import with the imported file
pagespeed EnableFilters flatten_css_imports;
pagespeed CssFlattenMaxBytes 5120;
# defer the loading of images which are not visible to the client
pagespeed EnableFilters lazyload_images;
# enable JavaScript minification
pagespeed EnableFilters rewrite_javascript;
# enable image optimization
pagespeed EnableFilters rewrite_images;
# pre-solve DNS lookup
pagespeed EnableFilters insert_dns_prefetch;
# rewrite CSS to load page-rendering CSS rules first.
pagespeed EnableFilters prioritize_critical_css;
# make Google analytics async
pagespeed EnableFilters make_google_analytics_async;
}
Test et validation
Il existe tout un tas d’outils pour tester la vitesse de chargement de vos pages. J’utilise personnellement GTMetrix et PageSpeed Insights. On peut ainsi facilement quantifier le gain de l’utilisation du module PageSpeed sur son site.
Il est clair que le module PageSpeed n’aura pas le même impact sur les les sites ayant pris en compte les problématiques de SEO et d’optimisation du chargement dès leurs conceptions que sur les autres. Mais au vu du faible overhead CPU et mémoire de ce module, je vous conseille de l’intégrer de base dans vos serveurs Web.
Utilisez-vous ce module (ou son pendant pour Apache ?) pour l’hébergement de vos sites ? Quels sont les filtres que vous mettez en place ?
Sur une idée originale pompée honteusement sur le blog de Bryan Kennedy.
La virtualisation ou la possibilité d’acheter des machines à bas prix comme le Raspberry implique le fait que l’installation de serveurs devient une tâche de plus en plus fréquente. Afin d’éviter les grossières erreurs qui peuvent rapidement devenir fatales si la machine est exposée au réseau Internet, voici les actions que j’effectue systématiquement sur mes systèmes d’exploitations Debian ou Ubuntu Server.
Si vous suivez ce blog, vous savez que je suis un gros fainéant pour ce genre de tâches récurrentes. J’ai donc écrit un ensemble de scripts permettant d’effectuer les actions de « post installation ». J’ai également commencé à regarder du coté des systèmes de gestion de configuration comme Puppet qui sont des solutions à utiliser en priorité si vous avez un parc informatique important.
L’objectif de ce billet est donc pédagogique pour partager avec vous les actions à effectuer et, je l’espère, en apprendre de nouvelles.
Assez de palabres, place au clavier…
1) S’occuper de ses comptes
Je parle bien évidemment ici des comptes utilisateurs qu’il va falloir sécuriser. On commence par le compte root qui ne sera PAS (jamais, c’est mal) utilisé directement pour vous connecter sur votre machine. Lors de l’installation du système, il faut saisir un mot de passe sécurisé, c’est à dire assez long avec un mélange de lettres, de chiffres et d’autres caractères mais sans utiliser des mots connus ou des suites de chiffres. Vous n’avez pas besoin de connaitre ce mot de passe par coeur mais il faudra le conserver bien au chaud.
Une fois logué sur la machine (on durant la phase d’installation du serveur), on commence par créer un utilisateur principal que l’on utilisera pour se connecter à la machine.
J’ai choisi morpheus pour illustrer mon billet.
useradd morpheus
mkdir /home/morpheus
La suite des opérations sera donc faite à partir de cet utilisateur.
2) S’occuper de ses portes d’entrées avec SSHd
SSH est devenu le mode d’accès le plus utilisé pour accéder aux serveurs GNU/Linux. Par défaut, il propose un contrôle d’accès par nom d’utilisateur et mot de passe. J’essaye au maximum d’éviter cette solution. J’utilise le système d’authentification par clé publique qui est un peu plus lourde à mettre en oeuvre et à administrer mais qui offre un niveau de sécurité plus important.
Pour ajouter la clé publique de mon PC avec lequel je vais me connecter au serveur, il suffit de lancer la commande suivante à partir de cette machine:
ssh-copy-id morpheus@monserveur
Puis on force l’utilisation de l’authentification par clé publique et on ferme ensuite cette porte à l’utilisateur root:
sudo vim /etc/ssh/sshd_config
PasswordAuthentication no
PermitRootLogin no
Attention: l’authentification par nom d’utilisateur / mot de passe sera désactivée pour les accès SSH.
On relance ensuite le daemon SSH:
sudo service ssh restart
3) Contrôler les entrées avec Fail2ban
Une fois le daemon SSH sécurisé, il faut ensuite ajouter une couche permettant de contrôler plus finement les accès. J’utilise pour cela Fail2ban que j’ai abordé plus précisément dans un précédant billet. Dans notre sujet du jour, je vais configurer Fail2ban pour bloquer, pendant 5 minutes, l’accès à SSH à un utilisateur qui se trompe 3 fois de mot de passe.
On commence par installer fail2ban:
sudo apt-get-install fail2ban
On va ensuite éditer le fichier /etc/fail2ban/jail.conf pour le configurer comme l’on souhaite:
On relance ensuite le service pour prendre en compte la configuration:
sudo service fail2ban restart
4) Fermer les fenêtres (de votre Firewall)
Comme nous l’avons vu dans le point précédant, Fail2ban utilise le Firewall IPtable qui part défaut laisse passer l’ensemble des flux. J’applique systématiquement une configuration beoucoup plus restrictive qui autorise les flux SSH entrant (pour l’accès à distance) et HTTP/HTTPs/DNS sortant (pour la mise à jour de mon serveur).
J’utilise pour cela un script de démarrage maison:
que je lance au démarrage de la machine (et aussi immédiatement):
sudo update-rc.d firewall.sh defaults 20
sudo service firewall start
Il est bien sûr possible d’adapter ce script à vos besoins de flux entrants et sortants en éditant les lignes suivantes:
# Services that the system will offer to the network
TCP_SERVICES="22" # SSH only
UDP_SERVICES=""
# Services the system will use from the network
REMOTE_TCP_SERVICES="80 443" # web browsing
REMOTE_UDP_SERVICES="53" # DNS
5) Prendre soin de ses fondations en tenant son système à jour
Maintenir à jour ses serveurs est une tâche à la fois indispensable et rébarbative. Il y a ici deux écoles possibles. La première est d’utiliser un logiciel comme unattended-upgrades qui va installer automatiquement pour vous les mises à jours de sécurités ou même l’ensemble de votre système. C’est une solution élégante mais qui n’est pas sans risque si un pépin arrive suite à une mise à jour alors que vous êtes loin de vous machines. J’opte donc pour la seconde solution, basée sur cron-apt, qui va me notifier par mail les mises à jours à effectuer sur mes machines.
On installe cron-apt avec la commande:
sudo apt-get install cron-apt
Puis on configure l’adresse mail de destination des messages de notifications dans le fichier /etc/cron-apt/config:
MAILTO="bibi+monserveur@gmail.com"
Note: comme vous pouvez le lire, j’utilise une adresse Gmail bibi@gmail.com pour la réception de mes notifications. J’y ajoute +monserveur (qui sera ignoré par Gmail) afin de pouvoir facilement les filtrer.
On relance le service pour prendre en compte la configuration:
sudo service cron-apt restart
Les notifications seront envoyés par défaut toutes les nuits à 4h du matin.
6) Surveiller le tout avec Logwatch
A ce stade vous avez un serveur disposant d’une sécurité de base qui va le protéger de la grande majorité des attaques que l’on peut trouver sur Internet. Il ne reste plus qu’à installer Logwatch, un outil permettant d’analyser les logs et ainsi de remonter par mail des rapports permettant d’analyser des tentatives d’intrusions éventuelles.
La mise en place est assez simple.
sudo apt-get install logwatch
Puis on configure l’adresse mail de destination des messages de notifications dans le fichier /etc/cron-apt/config:
#execute
/usr/sbin/logwatch --output mail --mailto bibi+monserveur@gmail.com --detail high
On relance le service pour prendre en compte la configuration:
sudo service cron-apt restart
Les notifications seront envoyés par défaut toutes les nuits.
7) Conclusion
Nous arrivons à la fin de ce billet avec une machine à l’épreuve d’une exposition à Internet sans risque de se faire hacker par le premier « script kiddie » venu.
A vous de nous faire partager vos techniques, méthodes que vous appliquez sur vos nouveaux serveurs !
Grâce au travail de Nicolas Bourges, Glances dispose désormais d’un installeur pour sa version Windows. Vous pouvez donc installer Glances 1.6.1 en version 32 ou 64 bits sans avoir à installer les pré-requis (Python, librairie PsUtil…) puisque tout est « packagé » dans le binaire.
On commence par télécharger le programme d’installation:
Puis on se laisse guider dans le wizard d’installation qui va mettre, par défaut, le binaire Glances.exe dans le répertoire C:\Program Files\Glances puis créer un raccourci sur votre bureau.
En cliquant sur ce raccourci, Glances va se lancer automatiquement en mode serveur. Pour ajouter d’autres paramètres (comme le mot de passe) il suffit de modifier ce raccourci pour y ajouter les options voulues (par exemple -P <motdepasse>).
Il ne vous reste plus qu’à revenir sur un vrai OS (ndlr: Nicolargo, tu me copieras 100 fois « Je ne trollerai plus. ») puis à lancer la commande:
glances -c <addresse IP machine Windows>
Et hop, vous pouvez maintenant surveiller vos machines Windows en une ligne de commande !
Il s’est écoulé quelques mois depuis mon premier billet sur les logiciels libres de gestionnaires de configurations de machines. Ce laps de temps m’a permis de consulter un nombre important d’articles, de forum et de littérature. Il est donc maintenant temps de partager cela avec vous.
J’avais initialement prévu de faire un seul gros article, mais devant le nombre important de choses à dire et la complexité du sujet, j’ai préféré le découper en plusieurs parties.
La première, que vous êtes en train de lire est une introduction à Puppet ou l’on va détailler l’installation (serveur et cliente) et la configuration initiale du système. Viendront ensuite des billets spécifiques sur la définition des sites et noeuds puis un ou plusieurs autres sur les modules.
Introduction
Puppet est donc un « gestionnaire de configurations de machines ». Derrière ce terme un peu barbare se cache la possibilité de centraliser la configuration système de vos machines au sein d’un référentiel unique. Le procédé peut très bien s’appliquer à une seule machine ou à un parc important et hétérogènes.
Puppet fonctionne sur le principe de clients (installé sur les machines de votre parc) et d’un serveur (installer sur un ou plusieurs serveurs de votre réseau). Puppet permet ainsi de s’assurer qu’à un instant t, toutes les machines clients sont dans un état de configuration défini sur le serveur.
Pour des besoins de tests il est tout à fait envisageable d’héberger à la fois le client et le serveur sur une seule et même machine. J’ai choisi, pour illustrer cet article, d’une architecture un peu plus proche de la réalité:
Puppet « testbed »
Pourquoi Puppet et non pas Chef ou CfEngine ?
Tout simplement la solution qui m’a semblé la mieux documentée et avec un nombre important de ressources (blog / forum) sur le sujet. Chaque solution a ses avantages, je vous laisse chercher sur votre moteur de recherche préféré les différents articles permettant de les comparer et de choisir celle qui s’adaptera le mieux à vos besoins et surtout avec votre manière de fonctionner.
Installation du serveur Puppet (aka PuppetMaster)
La version 2.6.6 est disponible dans les dépôts officiels de la Debian 6 (Squeeze) au moment de la rédaction de ce billet. Afin de permettre une utilisation avec les clients en 2.7 (version actuellement packagée sous Ubuntu 12.04), il est nécessaire de passer par le dépôt backports que l’on installe de la manière suivante:
# sudo vi /etc/apt/sources.list.d/backports.list
deb http://backports.debian.org/debian-backports squeeze-backports main
L’installation du serveur (module PuppetMaster) et de ses dépendances se fait sur une distribution GNU/Linux Debian 6 via les commandes suivantes (en root ou précédée de sudo):
Une commande permet de s’assurer que le serveur est bien lancé:
$ sudo service puppetmaster status
master is running.
Attention: Si votre serveur est protégé par un Firewall alors il faut penser à ouvrir le port TCP/8140 qui est le port par défaut, sinon les clients n’arriveront pas à le joindre. Si votre serveur est hébergé derrière un réseau NAT, il faudra également rediriger le port TCP/8140 vers votre machine.
Installation d’un client Puppet (Debian ou Ubuntu)
Encore plus simple est l’installation d’un client Debian (sur laquelle le dépôt backport a été ajouté):
sudo apt-get -t squeeze-backports install puppet
ou Ubuntu en utilisant la commande suivante (en root ou précédée de sudo):
sudo apt-get install puppet
Pour fonctionner, le client Puppet a besoin de connaitre l’adresse du serveur (PuppetMaster). On doit donc éditer, sur la machine cliente, le fichier /etc/puppet/puppet.conf et y ajouter la ligne suivante dans la section [main]:
server=<@IP ou NOM du serveur>
Attention: si vous utilisez un nom, ce qui est conseillé, il faut bien s’assurer que la résolution s’effectue correctement à la fois sur le serveur et sur les clients.
Pour sécuriser la connexion entre les clients et le serveur, Puppet utilise des tunnels SSL. Ces derniers nécessitent une phase d’initialisation à faire seulement une fois lors de la configuration du client. On commence par lancer la commande suivante sur le client (en root ou précédée de sudo):
client$ sudo puppetd -t -v -w 60
info: Caching certificate for ca
info: Creating a new SSL certificate request for optiplex790
info: Certificate Request fingerprint (md5): E2:D6:FB:1C:7C:36:96:D8:45:92:84:E3:71:F4:C6:BD
info: Caching certificate for optiplex790
On demande ensuite, sur le serveur, la liste des certificats SSL en attente de validation (en root ou précédée de sudo):
Nous avons donc une machine identifié par le nom « optiplex790 » (le nom de ma machine cliente) qui nécessite d’être autorisé par le serveur. Pour effectuer cette tache d’autorisation, on doit valider son certificat (en root ou précédée de sudo):
serveur$ sudo puppetca --sign optiplex790
notice: Signed certificate request for optiplex790
notice: Removing file Puppet::SSL::CertificateRequest optiplex790 at '/var/lib/puppet/ssl/ca/requests/optiplex790.pem'
Remarque: il est également possible de forcer l’authentification pour une plage d’adresses IP donnée. Cela représente tout de même une faille de sécurité qui est difficilement acceptable sur une réseau en production.
Il ne reste plus, sur le client, qu’à éditer le fichier /etc/default/puppet pour automatiser le lancement de Puppet au démarrage de la machine:
# Start puppet on boot?
START=yes
Et enfin à relancer le daemon du client en tache de fond:
sudo /etc/init.d/puppet start
Pour les phases de tests (par exemple lors de la mise en place de nouveaux modules), il est conseillé de désactiver le demon sur les clients…:
sudo /etc/init.d/puppet stop
… et de le lancer à la main et en mode « verbeux »:
La procédure d’installation se trouve ici. Sous Winddows 7, le fichier de configuration puppet.conf ou il faudra configurer l’adresse du PuppetMaster se trouve dans le répertoire C:\ProgramData\PuppetLabs\puppet\etc.
Pour lancer Puppet client, il suffit ensuite de lancer une premier fois Puppet à partir du menu Démarrer > Programmes > Puppet > Run Puppet Agent. Ce dernier va afficher un message comme quoi le serveur n’arrive pas à l’identifier. On doit, comme pour les client GNU/Linux forcer l’authentification avec la commande suivante sur le serveur:
sudo puppetca --sign win7
Le prochain lancement de Puppet (menu Démarrer > Programmes > Puppet > Run Puppet Agent) devrait se faire sans problème.
Et hop passons aux choses sérieuses…
Configuration de votre référence: le serveur Puppet
Toute la configuration (référentiel) de Puppet est centralisé dans l’arborescence /etc/puppet de votre serveur fraichement installé. Dans le « best practice » de Puppet, il est fortement conseillé de gérer ce répertoire (et ce qu’il contient) en configuration (sous CVS, SVN ou GIT). C’est dans ce répertoire que nous allons définir notre site (réseau), nos noeuds (machines) et les modules (actions) à appliquer lors de la mise en configuration.
Commençons par une rapide description des fichiers contenus dans ce répertoire:
/etc/puppet/manifests/site.pp: C’est le premier fichier analysé par PuppetMaster pour définir son référentiel. Il permet de définir des variables globales et d’importer des modules (ensembles de classes) ainsi que des fichiers templates et noeuds de votre réseau. Attention de ne pas définir directement les templates et les noeuds dans ce fichier… C’est techniquement faisable mais pas très propre à maintenir.
/etc/puppet/manifests/template.pp: (optionnel) Permet de définir ou d’étendre (notion d’héritage comme en POO) des classes spécifiques à votre réseau.
/etc/puppet/manifests/node.pp: Permet de définir les noeuds (machines) de votre réseau. Il est conseillé de défini le nom d’un noeud par le nom FQDN de la machine. Si votre réseau est important (plusieurs centaines de machines à gérer), il est tout à fait possible de créer une arborescence dédié avec un fichier node.pp par sous-réseau.
/etc/puppet/modules/<module>/: Sous répertoire contenant la définition du module (action). Un fichier <module>/manifests/init.pp contient la définition du module (en clair c’est ici que l’on va définir ce que l’on doit faire sur la machine cliente) et le répertoire <module>/files/l’ensemble des fichiers nécessaires à l’exécution de ce module. Voyons maintenant le détail de ces fichiers.
Définition de votre site (réseau Puppet)
Idéalement, le fichier site.pp ne doit contenir que des lignes import (permettant d’importer les autres fichiers de configuration) et la définition des variables globales (nécessaire à plusieurs modules).
Les deux premières lignes définissent les paramètres permettant aux client d’accéder au serveur de fichier PuppetMastert en indiquant notamment le nom FQDN du serveur Puppet (à adapter à votre configuration). Attention de bien vérifier que les machines clients arrive bien à résoudre le nom FQDN en question. La troisième ligne demande au serveur de prendre en compte tous les noeuds disponibles dans le fichier node.pp.
Définition de vos noeuds (machines clientes Puppet)
Nous allons utiliser le fichier node.pp pour définir les configurations à appliquer sur les machines clientes de notre réseau. Par exemple pour définir le noeud nommé optiplex790 (machine dont nous avons validés l’authentification dans le chapitre précédant) et y appliquer le module dummy, il faut éditer le fichier /etc/puppet/manifests/node.pp en y ajoutant les lignes suivantes:
node 'optiplex790' {
include dummy
}
Le module dummy va être défini dans le paragraphe suivant.
Définition des modules (actions à appliquer sur les machines clientes Puppet)
Chaque module dispose de son propre répertoire sous /etc/puppet/modules/<module>. Ainsi on commence par créer l’arborescence du module dummy:
Le premier répertoire (manifests) va contenir la définition de l’action. Le second (files), les optionnels fichiers permettant d’effectuer cette action. On défini l’action dummy en créant le fichier /etc/puppet/modules/dummy/manifests/init.pp avec le contenu suivant:
class dummy {
file { "/etc/puppet.txt":
owner => root,
group => root,
mode => 644,
source => "puppet:///dummy/puppet.txt"
}
}
Le module dummy va donc vérifier:
l’existence sur la machine cliente d’un fichier /etc/puppet.txt
appartenant à l’utilisateur root
appartenant au groupe root
avec les droits 644
et dont le contenu doit être égal au fichier /etc/puppet/modules/dummy/files/puppet.txt disponible sur le serveur
Prise en compte de la nouvelle référence par le serveur
Pour que PuppetMaster prenne en compte al nouvelle référence que nous venons de définir, il faut relancer le démon avec la commande (en root ou avec sudo):
sudo service puppetmaster restart
Forcer la mise en configuration sur vos clients Puppet
Pour tester la configuration, nous allons lancer la commande suivante sur le noeud optiplex790 (machine sous Ubuntu 12.04):
sudo puppetd -t -v
Si vous rencontrez l’erreur suivante sur votre client:
err: Could not retrieve catalog from remote server: Error 400 on SERVER: No support for http method POST
warning: Not using cache on failed catalog
err: Could not retrieve catalog; skipping run
C’est probablement que vous utilisez une version du client Puppet supérieure à PuppetMaster (par exemple un Puppet client 2.7 avec un PuppetMaster 2.6). Un bug report est disponible ici. Avec la même version des deux cotés et si tout ce passe bien le message suivant devrait s’afficher:
info: Caching catalog for optiplex790
info: Applying configuration version '1346169168'
notice: /Stage[main]/Dummy/File[/etc/puppet.txt]/ensure: defined content as '{md5}1425249a5cbdea520b7a1a23f7bc2153'
info: Creating state file /var/lib/puppet/state/state.yaml
notice: Finished catalog run in 0.64 seconds
Dans le cas ou tout se passe correctement, vous devriez alors trouver un nouveau fichier puppet.txt dans votre répertoire /etc:
Maintenant que vous avez les bases permettant d’associer des actions à des machines, seule votre imagination vous posera des limites. Cependant, avant de partir bille en tête dans le développement de nouveaux modules, je vous conseille de regarder du coté de la Forge Puppet qui est un site communautaire permettant de partager, rechercher et récupérer des modules pour un nombre très important de cas. C’est également un très bon moyen d’apprendre le langage utilisé par Puppet en récupérant et lisant le code des modules.
Pensez également à partager vos modules !
En cas de problèmes…
Si vous rencontrez un problème lors de la configuration de votre Puppet Master, le plus simple est d’ouvrir une console et de surveiller la log des demons en filtrant un peu la sortie:
et de lancer la commande coté client en mode debug:
client$ sudo puppetd -t -v -d
Conclusion
Nous venons donc de faire nos premiers pas dans le très compl[et|exe] monde de Puppet. L’investissement nécessaire à l’administrateur est à la hauteur du gain de temps, de traçabilité et d’efficacité qu’il obtiendra en fin de projet.
A très vite pour la suite des billets sur Puppet !
C’est suite à un tweet sur l’abandon du développement de la version GNU/Linux de Picassa par les équipes de Google que j’ai entendu parler pour la première fois du projet OpenPhoto (bien que comme nous allons le voir les deux sujets ne soient pas liés).
OpePhoto propose d’héberger dans un « cloud » vos photos, permettant ainsi un accès dématérialisé (plus besoin d’apporter sa clé USB pour montrer les photos de vacances à ses parents/amis).
OpenPhoto propose pour cela deux solutions:
un service en ligne proposant de gérer vos photos (importation, catégories, tag, applications smartphones, API…) mais en les hébergeant dans votre « cloud » (Dropbox ou votre espace de stockage Amazon S3 et prochainement Google Drive).
une version communautaire et libre permettant d’auto-héberger son propre serveur. Cette version propose en plus un stockage local des photos (sans passer par Dropbox ou Amazon S3).
C’est sur cette deuxième configuration que nous allons nous pencher dans ce billet en proposant une procédure d’installation et de configuration de Open Photo sur une machine Debian Squeeze avec NGinx , PHP-FPM et MySQL (la procédure doit être la même sous Ubuntu, mais je n’ai pas vérifié).
Note: à l’heure de la rédaction de ce billet, il y a peu ou très peu de documentation sur le Web sur comment installer OpenPhoto sur un serveur Nginx (alors que l’on trouve un tas de procédure pour les autres serveurs Web du marché sur le GitHub officiel…). Si une âme généreuse veut proposer une adaptation de ce billet dans le même formalisme que l’installation sous Apache, je pense que le projet serait très reconnaissant… (je m’en suis chargé).
Préparation de l’installation
Je pars sur le principe ou vous avez une machine Debian sur laquelle Nginx et PHP-FPM sont déjà installé. Si ce n’est pas le cas, vous pouvez suivre ce billet.
En plus, il faudra installer les paquets suivants:
On configure PHP en éditant les variable suivantes dans le fichier /etc/php5/fpm/php.ini (à adapter à votre besoin, notamment si vous avez un appareil photo avec un capteur générant des images > 16 Mo):
file_uploads = On
upload_max_filesize = 16M
post_max_size = 16M
On active également l’oAuth (pour l’authentification des applications tierces comme par exemple les applis iPhone et Android):
On redémarre PHP-FPM pour prendre en compte les modifications:
sudo service php-fpm restart
Installation de OpenPhoto
On créé ensuite un répertoire dans notre serveur Web (/var/www/openphoto) et on télécharge la dernière version de la version communautaire (libre) de OpenPhoto:
Enfin on génère le fichier de configuration Nginx /etc/nginx/sites-enabled/openphoto pour le site OpenPhoto (à adapter également à votre configuration, notamment au niveau du server_name):
server {
listen 80;
server_name openphoto.mondomaine.com;
root /var/www/openphoto/src/html;
index index.php;
client_max_body_size 25M;
default_type text/html;
charset utf-8;
if (!-e $request_filename) {
rewrite ^/([^?]*)(\?+([^?]*))*$ /index.php?__route__=/$1&$3 last;
}
# PHP scripts -> PHP-FPM server listening on 127.0.0.1:9000
# Check cache and use PHP as fallback.
location ~* \.php$ {
try_files $uri =404;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_ignore_client_abort off;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}
# Global restrictions configuration file.
location = /favicon.ico {
log_not_found off;
access_log off;
}
location = /robots.txt {
allow all;
log_not_found off;
access_log off;
}
location ~ /\. {
deny all;
access_log off;
log_not_found off;
}
location ~ \.ini$ {
deny all;
access_log off;
log_not_found off;
}
add_header Cache-Control "max-age=315360000";
# Mise ne cache des ressources statiques
location ~* ^.+\.(jpg|jpeg|gif|css|png|js|xml)$ {
expires 30d;
access_log off;
}
}
On redémarre NGinx pour prendre en compte le site:
sudo service nginx restart
Puis on crée une nouvelle base de donnée MySql. Notez sur une feuille, le nom de la base (openphoto), le nom de l’utilisateur (openphoto) et le mot de passe associé (openphotomdp2012):
# mysql -u root -p
Enter password:
mysql> create database openphoto;
Query OK, 1 row affected (0.00 sec)
mysql> GRANT ALL PRIVILEGES ON openphoto.* TO "openphoto"@"localhost" IDENTIFIED BY "openphotomdp2012";
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
mysql> exit
Bye
Configuration initiale de OpenPhoto
La suite de la configuration se fera à partir d’un navigateur Web, plus besoin de la ligne de commande :).
On doit dans un premier temps créer un compte sur le site OpenPhoto (même si on utilise pas la version en ligne et seulement une version auto-hébergé). Une fois le mail de confirmation reçu et la confirmation effectué, vous pouvez poursuivre l’installation en vous rendant à l’URL: http://openphoto.mondomaine.com (remplacer mondomaine.com par votre domaine que vous avez configurez dans le fichier de configuration NGinx). Si vous n’avez pas de domaine, il est possible de passer directement par l’adresse IP de votre machine.
Vous devez arriver sur la page suivante:
On entre:
l’adresse email associé à votre compte OpenPhoto
on laisse le thème par défaut et on clique sur « Continue to step 2 »
On passe à la deuxième étape de l’installation:
On sélectionne:
une base de donnée de type MySQL (que l’on a préalablement créer dans le chapitre précédant)
un stockage local des photos (on peut noter qu’il est possible de mixer stockage local et Dropbox)
on passe à la troisième et dernière étape
Elle permet de configurer notre base de donnée MySQL (reprendre votre petite feuille…):
A la fin de cette procédure, votre serveur OpenPhoto est prêt !
Prise en main et premières impressions
La première chose à faire est d’importer quelques photos. On peut utiliser la page Upload qui propose une importation par Drag & Drop (ou sélection plus classique dans le gestionnaire de fichiers) ou bien l’application dédiée de votre SmarthPhone (Android et iPhone). Les images sont téléchargés sur votre serveur avec une très élégante barre de progression. On note au passage qu’OpenPhoto utilise les dernières technologies HTML5.
On peut ensuite éditer les images en y ajoutant une description, des tags, des coordonnées GPS, des droits (public ou privé) et une licence. Ces informations sont bien sûr récupérées automatiquement si elles sont présentes dans les méta-données du fichier.
Elle est pas belle ma fille ? 🙂
OpenPhoto permet de créer des groupes d’utilisateurs ayant des droits sur certaines photos. Par exemple, si vous créez un groupe Famille, alors il sera possible de classer vos photos familiales dans ce groupe afin qu’elles ne soient visibles que par vos proches. Pour grouper vos photos dans des groupes, le plus simple est d’aller dans le menu Manage, de sélectionner les photos en question (par un simple clic sur le bouton pin) puis de cliquer sur le bouton « Batch edit » et enfin de séléctionner le groupe.
Mes premières impressions sont très bonnes. OpenPhoto est rapide, stable. Le seul problème que j’ai rencontré est au niveau de l’affichage de la Gallery ou les photos sont déformées. Je vais essayer de le pousser un peu en important un grand nombre d’images (je ferai une màj du billet).
On sent une grande marge de manoeuvre au niveau des fonctionnalités proposées. Il est d’ailleurs possible de voter avec la communauté pour influencer la roadmap du logiciel sur les futures fonctions. J’aime le fait qu’OpenPhoto se concentre uniquement sur la gestion des images, contrairement à OwnCloud dont j’avais parlé dans un précédent billet.
Que pensez-vous de ce genre de service ?
Êtes vous prêts à franchir le pas et d’auto-héberger vos photos sur une de vos machines ?
Si vous suivez régulièrement ce blog, vous savez que je suis un informaticien fainéant, j’ai horreur de faire plusieurs fois la même chose. C’est une des raison pour laquelle je développe des scripts d’auto (ou post) installation que vous pouvez trouver sur mon espace GitHub.
Nous allons, dans ce billet, parler de la nouvelle version du script de post installation de la version Ubuntu Precise Pangolin (aka 12.04 LTS).
Heu, c’est quoi un script de post install ?
C’est un script que l’on lance à la fin d’une installation « standard » (« out of the box ») d’un système d’exploitation et qui va s’occuper de le configurer pour répondre au mieux à nos besoins.
On peut par exemple automatiser les tâches suivantes:
ajouter les dépôts de logiciels
installer les logiciels que vous jugez indispensables
supprimer les logiciels inutiles
télécharger et installer des thèmes pour votre interface graphique
configurer vos applications (BASH, prompt, Vim…)
faire toutes les actions en ligne de commande qui vous passe par la tête !
Historique du script UbuntuPostInstall
Les dernières versions de ce script (pour les distributions Ubuntu 11.04 et 11.10) étaient développées en Shell Script (BASH). Afin de simplifier le développement, j’ai donc décidé de re-développer complètement le script en Python en lui apportant une fonction de personnalisation par fichier de configuration.
C’est donc sur cette base que le script pour la version 12.04 d’Ubuntu est développé.
Comment fonctionne le script ?
Le script, disponible sous GitHub ou à partir de sa page officielle, est autonome et fonctionne directement à partir d’une installation standard d’Ubuntu 12.04 LTS. Pour le télécharger, il faut saisir les commandes suivantes:
Pour fonctionner, le script utilise un fichier de configuration qui permet de spécifier les « choses à faire ». Par défaut, si aucun configuration n’est spécifiée dans la ligne de commande, il va télécharger le fichier suivant sur mon GitHub: post-installation pour Unity.
Donc pour lancer une post-installation standard sur une toute fraiche distribution Ubuntu 12.04 LTS, il faut lancer la commande:
sudo ./ubuntu-12.04-postinstall.py
Le script va faire les chose suivantes:
Ajouter des dépôts PPA utiles (voir la liste dans la section repos)
Ajouter des applications indispensables aux geeks (classées par thème: dev, multimedia, réseau, système…)
Ajout de thèmes pour GTK, des icônes…
Configuration de BASH (.bashrc, prompt, alias), Vim (.vimrc) et Htop (.htoprc)
Voici un aperçu du script en cous d’exécution:
Le script génère également un fichier de log dans le répertoire /tmp qui va détailler toutes les actions effectuées (et vous permettre d’identifier les éventuels problèmes).
D’autres fichiers de configuration sont disponibles sur mon GitHub et peuvent être spécifiés dans la ligne de commande. Par exemple, si vous préférez utiliser Gnome Shell en lieu et place d’Unity:
Comment éditer votre propre fichier de configuration ?
Bien que les fichiers fournis en standard répondent aux besoins de la plupart des geek qui lisent ce blog, il peut être intéressant de l’adapter plus finement à vos besoins.
Le plus simple est donc de « forker » la configuration par défaut qui s’approche le plus de votre environnement (Unity, Gnome Shell ou Cinnanon). Puis d’éditer le fichier de configuration et enfin de l’utiliser avec l’option -c du script (qui peut prendre en paramètre une URL ou un fichier local).
Comme vous allez le voir, le fichier de configuration permet, en plus des actions détaillées au début de ce chapitre, de lancer des lignes de commandes en début (section preactions) ou fin de script (section postactions).
Conclusion
Si vous avez des remarques ou des demandes spécifiques sur ce nouveau scripts ou que vous vouliez partager vos fichiers de configurations personnels, les commentaires ci-dessous sont là pour ça !
Grâce à Arnaud Hartmann (un grand merci à lui), un PPA est maintenant disponible pour installer la dernière version stable de Glances sur votre système Ubuntu (ou dérivé).
Le PPA en question couvre les versions d’Ubuntu depuis la 9.10 (Karmic) jusqu’à la future 12.04 (Precise Pangolin).
Pour installer Glances sur votre système via ce PPA, il suffit d’effectuer les actions suivantes:
A la date de la rédaction de ce billet, la dernière version stable disponible est la 1.3.7. Pour les plus téméraires, il est possible, en parallèle de cette installation, de tester la version expérimentale (1.4b) en utilisant le PPA suivant en lieu et place du stable: ppa:arnaud-hartmann/glances-unstable
Je viens de finaliser l’installation sur mon PC portable perso (le pro reste sous Debian Stable) de la toute dernière version d’Ubuntu Desktop: Oneiric 11.10. Voici donc les actions que j’ai suivi pour en faire mon système maison.
Le script de post-install
Comme j’aime partager, j’ai mis sur mon GitHub la version du script de post install pour cette version d’Ubuntu. Pour l’installer et l’executer sur un système fraichement installé, il suffit de lancer les commandes suivantes:
Il faut être patient car le script prend un certain temps à s’exécuter…
Que va faire ce script ?
Installer une liste impressionnante de logiciels que je trouve utile (la liste se trouve ici). Libre à vous de modifier le script pour l’adapter à vos besoins. On peut citer Dropbox, Google Earth, Jupiter (pour les PC portables)…
Installer Gnome Shell (Gnome 3) car je n’arrive pas à me faire à Unity (je suis sûrement trop vieux).
Installer un thème pour ce même Gnome Shell.
Faire quelques configurations systèmes (remettre les icônes d’agrandissement et de réduction des fenêtres, passer la barre de notification dans celle du haut, ajout d’alias dans le .bashrc…).
A noter que pour finaliser l’installation de Dopbox, il faut lancer l’application après la fin du script.
Configuration à la mimine
Il reste maintenant à mener des actions qui ne sont pas automatisable par le script de post install.
Update: les 2 premières étapes sont maintenant automatisées par le script (merci à Makidoko).
Etape 1 – On passe sous Gnome Shell
Après un bon petit reboot, vous allez normalement arriver sur le gestionnaire LightDM ou il faudra sélectionner GNOME (Gnome Shell) comme interface utilisateur en lieu et place d’Ubuntu (UNITY).
Devant vos yeux ébahis, vous devriez avoir l’interface Gnome Shell par défaut.
Etape 2 – On change de (Gnome) thème
Pour sélectionner un thème plus agréable à ces mêmes yeux, il suffit de lancer l’utilitaire Gnome Tweak Tool:
d’appuyer sur la touche SUPER (Windows) de votre clavier
entrer « gnome tweak tool » dans la zone de recherche
cliquer sur l’icône Advanced Settings
Puis quand le logiciel est lancé, il faut se rendre dans le menu Shell Extensions et activer le plugin User Themes Extension qui va prendre en compte les thèmes qui se trouve dans le répertoire $HOME/.themes.
Il faut ensuite relancer Gnome Tweak Tool puis aller dans le menu Theme et sélectionner Faience. En bonus, j’utilise les icônes Faenza-Dark.
Etape 3 – On configure sa barre de lancement
Ici c’est affaire de goût, personnellement, j’ai les applications suivantes:
Chromium, the navigateur Web (même si il m’arrive d’utiliser Firefox en //)
Terminator, parce que les lignes de commandes il n’y a rien de mieux
VLC, c’est français, léger, rapide, complet… Le top du multimédia
Shutter, pour faire de beaux screenshots
Spotify car ma musique est virtuelle
Voila un petit aperçu final:
Et de votre coté, vous avez switchés vers la 11.10 ? Cela donne quoi ?
Si vous avez essayé d’installé la dernière version en date de Nagios sur votre système, il se peut que l’erreur suivante soit apparue lors du « make fullinstall »:
C’est en fait au niveau de l’installation du nouveau thème de l’interface Web de Nagios que le bas blesse et notamment au niveau du fichier Makefile qui se trouve dans le sous répertoire ./html.
Pour résoudre ce problème et procéder à une installation complète de Nagios 3.3.1, il faut suivre la procédure suivante (en attendant le patch de la part de Nagios qui devrait bientôt arriver dans la version 3.3.2):
./configure
sed -i ‘s/for file in includes\/rss\/\*\;/for file in includes\/rss\/\*\.\*\;/g’ ./html/Makefile
sed -i ‘s/for file in includes\/rss\/extlib\/\*\;/for file in includes\/rss\/extlib\/\*\.\*\;/g’ ./html/Makefile
Donc si vous avez utilisé mes scripts pour installer et ou mettre à jours en version 3.3.1, je vous conseille de récupérer le script de mise à jour automatique de Nagios et de le ré-exécuter sur vos serveurs afin de finir proprement votre installation et disposer du nouveau thème Web:
Merci aux lecteurs qui on permis d’identifier le problème 🙂