Pour nous parler de Nagios et de supervision distribuée, j’ai le plaisir d’accueillir sur ce blog, en tant que rédacteur invité, Laurent Hugot. Laurent travaille actuellement pour la société Altair en Belgique et à en charge les activités de supervision.
===
Le « Distributed Monitoring » est une solution utilisée lorsque l’on veut surveiller plusieurs sites avec une seule installation de Nagios, qu’elle soit redondante ou non. La solution mise en avant dans ce billet est Mod-Gearman qui est un module Nagios abouti, performant et fiable.
Que nécessite cette solution ?
Le DistributedMonitoring de Nagios avec Mod-Gearman nécessite au minimum deux éléments :
- Un serveur qui sera à la fois le serveur Nagios et le serveur de jobs Mod-Gearman
- Un Worker qui peut être indépendant ou présent sur le serveur de jobs Mod-Gearman
Comment cela fonctionne-t-il ?
Mod-Gearman fonctionne de cette façon :
- Un côté Job Server qui distribuera les jobs et rapatriera les résultats
- Et un côté Worker qui réalisera les checks sur les hôtes de ses hostgroups
De manière plus précise le fonctionnement détaillé est le suivant:
- Le serveur de Jobs attend d’être contacté par des workers
- Lorsque les workers contactent le job server , ils s’authentifient auprès de lui, et il les répertorie
- Le serveur de jobs dispose d’un Event Broker que l’on insère dans Nagios
- Il remplacera donc la partie de Nagios qui réalise les checks, pour pouvoir les distribuer à sa guise
Un worker peut avoir plusieurs hostgroups d’assignés. Pour chaque hostgroup auquel il sera assigné, il prendra les jobs que le serveur de jobs mettra à disposition.
Côté technique
Le serveur de Jobs ne contacte pas les workers. Ce sont les workers qui contactent le serveur de jobs.
Cela implique qu’il soit joignable depuis l’extérieur, mais cela implique surtout que vos workers , à l’abris derrière des firewalls bien configurés, pourront communiquer sans le moindre souci avec votre serveur de jobs. Cela vous épargne de devoir percer le moindre trou dans les Firewalls de vos précieux clients.
Les connexions entre vos workers et votre (ou vos) job server(s) sont chiffrées, vous pouvez configurer votre structure pour désactiver ce chiffrement, si vous le souhaitez. On peut configurer la structure pour gérer les hosts et les services ou alors gérer les hostgroups. Ici j’aborderai la solution Hostgroups, pour le distributed monitoring, le mode host&services serait plutôt du failOver et loadbalancing pur.
Côté pratique
Pour faire simple (mais alors vraiment simple): on installe le serveur jobs sur le serveur de Nagios, on configure le NEB (Nagios Event Broker) dans la configuration de Nagios, et ensuite on configure un worker par site à surveiller, on le branche et c’est terminé. (Oui, aussi simple.)
Plus sérieusement : la configuration sera expliquée plus bas, mais le système est fait de telle façon à accueillir chaque worker qui se connecte au serveur de jobs, et de cette façon la distribution est totalement automatique tant que la configuration des hostgroups et du worker est faite comme il se doit.
Un peu de théorie
Avant de parler d’installation et de configuration, apprenons le concept, et le fonctionnement d’un Nagios fonctionnant avec un Mod-Gearman.
Voici un schéma illustrant mon serveur Nagios en production:
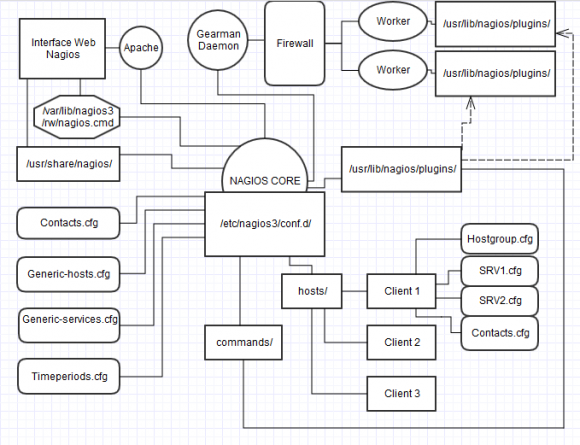
On voit ici la façon dont j’ai architecturé mon Nagios pour gérer des clients facilement.
Chaque dossier client qui se trouve dans /etc/nagios3/conf.d/hosts/ contient un fichier de définition de hostgroup , et un fichier par machine , et un dernier fichier comprennant les personnes de contact à mailer pour les alertes, et les plages horaires.
Le reste des fichiers de configuration sont dans /etc/nagios3/conf.d/
Ici sont les templates utilisés pour tous les clients , et les templates /contacts / timeperiods utilisés pour notre infrastructure.
J’ai représenté deux workers qui contactent, à travers plusieurs Firewalls mon serveur de jobs , qui prend les checks à nagios et qui lui restitue les résultats.
Il n’y a pas de modifications à apporter à Nagios pour dire. Une mention pour chaque hôte lui spécifiant quel worker doit se charger de lui, un Event Broker dans /etc/nagios3/nagios.cfg et c’est tout. Pour le reste c’est de la config de Workers.
Préparatifs et installation étape par étape
Pour préparer un serveur de jobs et un worker, il faut suivre quelques étapes cruciales.
Nous avons besoin avant de commencer :
Un Serveur Nagios 3.4.1 sur une Debian 7 (la manœuvre ne diffère pas beaucoup selon les OS , juste la façon de compiler qui devrait être différente, mais je n’expliquerai ici que la méthode que j’ai réalisé pour Debian, travaillant exclusivement sur cet OS. Merci Antoine Habran 😀 )
Et en bonus : Un Worker Raspberry Pi mod. B. (ou sinon un autre pc.)
En bonus car on peut s’en passer, car le Job Server peut contenir un Worker. Mais l’idée c’est de mettre le Worker ailleurs sur le net et le voir contacter notre serveur, pas vrai ?
Explications
Nous allons télécharger et installer sur notre serveur Nagios « Gearmand » qui est le « moteur » de mod-gearman , et ensuite, mod-gearman. La seconde étape consiste à configurer Nagios en mode Broker et à configurer le job server. Ensuite, on passera à la création d’un hôte d’exemple pour expliquer comment il sera géré et que vous puissiez vous en inspirer. Pour terminer on configurera un Worker (je ferai un exemple d’un worker Raspberry Pi Mod.B et un worker sur un debian 7 normal sur VM machine physique)
Installation de Mod-Gearman
Ah ouais, là on y est ! les prochaines lignes vont décrire les étapes nécessaires a l’installation de mod-gearman , et on va procéder comme suit :
- Installation des packages pour l’installation
- Téléchargement de la source de Gearmand
- Décompression de la source Gearmand
- Compilation de Gearmand
- Installation de Gearmand
- Téléchargement de la source de mod-gearman
- Décompression de la source mod-gearman
- Compilation de mod-gearman
- Installation de mod-gearman
- Configuration du job server mod-gearman
- Configuration du N.E.B de Nagios
- Configuration du Worker mod-gearman
Là nous aurons un serveur mod-gearman complet et opérationnel.
Il ne manquera qu’un Worker pour surveiller un site distant, mais le serveur sera fonctionnel et autonome, déjà.
D’abord avant de faire quoi que ce soit, il faut installer tous les prérequis pour la compilation et l’installation de gearmand, et mod-gearman.
Donc , si vous avez bien mis à jour votre système (apt-get update , apt-get upgrade)
On lance ceci :
apt-get install libcurl4-gnutls-dev autoconf automake make gcc g++ netcat uuid-dev libltdl7 libltdl-dev libncurses5-dev libevent-dev libboost-dev libboost-graph-dev libboost-iostreams-dev libboost-program-options-dev build-essential libboost-thread-dev libcloog-ppl0
On devrait avoir à ce stade tous les éléments pour la compilation, sauf un (libgearman6) qui doit s’installer après.
On passe ensuite au téléchargement et décompression des sources de Mod-Gearman:
cd /tmp
wget https://launchpad.net/gearmand/1.2/1.1.9/+download/gearmand-1.1.9.tar.gz
tar zxvf gearmand-1.1.9.tar.gz
cd gearmand-1.1.9
Maintenant on prépare le système pour réaliser l’installation de gearmand dans le dossier /opt/ en faisant comme ça , on peut le mettre à jour très facilement et proprement , ou le supprimer. Tapons ces deux lignes :
echo «opt/lib/» /etc/ld.so.conf.d/opt_lib.conf
ldconfig
On lance l’installation:
./configure --prefix=/opt
make
make install
Et si jusqu’ici tout a bien fonctionné et que vous n’avez pas d’erreurs : Le plus dur est fait !.
Maintenant que Gearmand est installé, on peut installer Mod-Gearman.
cd /tmp
wget http://labs.consol.de/wp-content/uploads/2010/09/mod_gearman-1.4.2.tar.gz
tar zxvf mod-gearman-1.4.2.tar.gz
cd mod-gearman-1.4.2
Puis on lance l’installation:
./configure --prefix=/opt --with-gearman=/opt --with-user=nagios --with-init-dir=/etc/init.d
make
make install
make install-config
On doit maintenant copier un fichier vers /etc/init.d pour pouvoir lancer proprement gearmand.
cp ./extras/gearmand-init /etc/init.d/gearmand
ensuite il faut ajouter un shell a l’utilisateur Nagios
chsh nagios
>> /bin/bash
chmod –R 770 /opt/var/log/mod_gearman
chown –R nagios:nagios /opt/var/log/mod_gearman
Voila qui est fait.
Note: Correction du script de démarrage de Gearmand
Si vous subissez un plantage lorsque vous tentez de démarrer gearmand , (ce qui était systématiquement mon cas…) il y a une modification à faire dans le script de démarrage /etc/init.d/gearmand
Démarrez gearmand :
/etc/init.d/gearmand start
Si vous avez un crash, c’est quasi obligatoirement ceci : La ligne 89 du script contient un argument de verbosité qui fait planter gearmand.
Supprimez l’argument de verbosité dans cette ligne :
CMD= »$DAEMON -p $PORT -P $PIDFILE $OPTIONS –log-file=$LOGFILE –verbose=2 –listen=$LISTEN »
Et retirez le –verbose=2
Cette option, pour une raison qui m’échappe fait planter gearmand.
Si tout fonctionne, arrêtez Gearmand (On le rallumera plus tard).
/etc/init.d/gearmand stop
Configuration du Job Server sur le serveur
Configurons le serveur de jobs pour l’intégrer à nagios et le rendre prêt à accueuillir un worker.
Éditons le fichier de config /opt/etc/mod_gearman_neb.conf:
debug=0
logfile=/opt/var/log/mod_gearman/mod_gearman_neb.log
server=127.0.0.1:4730
do_hostchecks=yes
encryption=yes
key=Superpasswordquidéchire
use_uniq_jobs=on
localhostgroups=
localservicegroups=
queue_custom_variable=WORKER
result_workers=1
perfdata=no
perfdata_mode=1
orphan_host_checks=yes
orphan_service_checks=yes
accept_clear_results=no
Ici l’important, c’est la key, elle doit être identique sur votre fichier NEB et sur vos workers.
La « queue_custom_variable » est essentielle aussi, elle définit ce qui qualifie un worker pour la configuration d’un hôte. Vous verrez pourquoi on définit cette valeur plus loin.
On va passer au worker maintenant.
Configuration du Worker sur le serveur
On va configurer notre serveur pour qu’il surveille le site dans lequel il se trouve. En faisant cela, notre serveur Nagios – mod-Gearmand va surveiller le hostgroup dans lequel vous avez mis toutes vos machines, un peu comme avant l’installation de mod-gearman.
Pour ça , on édite le fichier /opt/etc/mod_gearman_worker.conf (avec quelques informations masquées… je conserve un peu de secret concernant mon infrastructure de production :D):
debug=0
hostgroups=hostgroup1-servers,hostgroup2-servers
logfile=/opt/var/log/mod_gearman/mod_gearman_worker.log
server=127.0.0.1:4730
encryption=yes
key=Superpasswordquidéchire
job_timeout=60
min-worker=5
max-worker=50
idle-timeout=30
max-jobs=1000
spawn-rate=1
fork_on_exec=no
load_limit1=0
load_limit5=0
load_limit15=0
show_error_output=yes
enable_embedded_perl=on
use_embedded_perl_implicitly=off
use_perl_cache=on
p1_file=/opt/share/mod_gearman/mod_gearman_p1.pl
workaround_rc_25=off
Voila, c’est une configuration basique, pour le worker du serveur. Ajoutez les hostgroups que vous souhaitez checker avec CE worker , le mot de passe partagé par le serveur et les workers, et l’ip du serveur. Le reste sert à gérer le comportement du worker, ses limites, seuils.
A partir de là , le système est prêt à fonctionner, mais… pas la configuration de Nagios. On va donc s’occuper de ça !
Configuration de Nagios
Nous devons éditer Nagios pour lui dire que maintenant c’est papa qui s’occupe des checks.
ATTENTION : Ne JAMAIS inclure ou retirer de module BROKER (comme on va faire là) a chaud, ne jamais modifier quelque fichier que ce soit d’un module BROKER a chaud.
Distinction entre fichiers de module et fichier de config de mod-gearman toutefois.
Mod-gearman est indépendant du module broker et peut être redémarrer pendant que nagios tourne. Pour l’inclusion du Broker dans nagios, on arrête celui-ci.
/etc/init.d/nagios3 stop
On va éditer son fichier de configuration /etc/nagios3/nagios.cfg
Broker_module=/opt/lib/mod_gearman/mod_gearman.o config=/opt/etc/mod_gearman_neb.conf
Note: En une ligne séparé d’un espace.
Configuration des hostgroups
Il nous est nécessaire d’avoir une configuration orientée hostgroups pour mettre en place votre architecture distribuée.
Je vais illustrer cette configuration comme sur le schéma du début du document. On va donc créer deux hostgroups : hostgroup1-servers et hostgroup2-servers :
touch /etc/nagios3/conf.d/hosts/client1/hostgroup1.cfg
touch /etc/nagios3/conf.d/hosts/client2/hostgroup2.cfg
ensuite on va ajouter des machines, il nous faut au moins une machine par hostgroup.
touch /etc/nagios3/conf.d/hosts/client1/serveurnagios.cfg
touch /etc/nagios3/conf.d/hosts/client2/serveurlambda.cfg
il nous faut un worker sur le site distant, disons que le client2 est a 200Km d’où je me trouve, je me rend sur place, je déploie un worker, dont on parlera plus bas, et je ne m’en occupe plus, mais il faut le surveiller aussi le petit coquin
touch /etc/nagios3/conf.d/hosts/client2/worker.cfg
Voici le fichier contenu de mon fichier hostgroup1.cfg:
define hostgroup{
hostgroup_name hostgroup1-servers
alias mes serveurs du hostgroup 1
members hostgroup1-serveurnagios
}
define hostextinfo{
hostgroup_name hostgroup1-servers
notes serveurs du hostgroup1
icon_image base/uneimage.png
icon_image_alt hostgroup1 logo
vrml_image base/uneimage.png
statusmap_image base/uneimage.png
}
Ici rien de spécial, comme vous le voyez. Le hostgroup est défini normalement.
Voici un fichier pour l’hôte « hostgroup1-serveurnagios » /etc/nagios3/conf.d/hosts/hostgroup1/serveurnagios.cfg
define host{
use generic-host
host_name hostgroup1-serveurnagios
alias hostgroup1-serveurnagios
address 127.0.0.1
_WORKER hostgroup_hostgroup1-servers
}
define service{
use generic-service
host_name hostgroup1-serveurnagios
check_command check_ssh
}
Voila un fichier d’hôte lambda, pour aller avec le fichier de hostgroup correspondant. J’ai mis un service lambda aussi, un check ssh.
Le second hostgroup sera comme suit :
define hostgroup{
hostgroup_name hostgroup2-servers
alias mes serveurs du hostgroup 2
members hostgroup2-serveurlambda,hostgroup2-worker
}
define hostextinfo{
hostgroup_name hostgroup2-servers
notes serveurs du hostgroup2
icon_image base/uneimage2.png
icon_image_alt hostgroup2 logo
vrml_image base/uneimage2.png
statusmap_image base/uneimage2.png
}
Voici le fichier hôte de la machine serveur lambda:
define host{
use generic-host
host_name hostgroup2-serveurlambda
alias hostgroup2-serveurlambda
address 192.168.1.200
_WORKER hostgroup_hostgroup2-servers
}
define service{
use generic-service
host_name hostgroup2-serveurlambda
check_command check_ssh
}
et le fichier de config du worker
define host{
use generic-host
host_name hostgroup2-worker
alias hostgroup2-worker
address 192.168.1.100
_WORKER hostgroup_hostgroup2-servers
}
define service{
use generic-service
host_name hostgroup2-worker
check_command check_ssh
}
Configuration du worker présent sur le serveur
Alez sur votre serveur éditer le fichier de config /opt/etc/mod_gearman_worker.conf et modifiez pour que la ligne:
hostgroups=
soit :
hostgroups=hostgroup1-servers
Démarrage de l’infrastructure
D’abord, on va démarrer Nagios, gearmand, ensuite le worker mod-gearman.
/etc/init.d/nagios3 start
/etc/init.d/gearmand start
Et ensuite :
su nagios -c '/etc/init.d/mod_gearman_worker start'
Le worker doit être démarré par l’utilisateur Nagios pour fonctionner. Donc on l’éxécute avec la commande su et l’option -c .
Pour faciliter les choses, éditez /etc/rc.local et ajoutez les deux lignes :
/etc/init.d/gearmand start
su nagios -c '/etc/init.d/mod_gearman_worker start'
Note: AVANT la ligne “exit 0” (sinon ça ne fonctionnera pas)
Et comme ça à chaque reboot vos services seront exécutés comme il se doit.
Là tout devrait tourner proprement, et les checks pour votre serveur Nagios être exécutés, pas les autres.
Le worker du hostgroup2 et le serveur lambda du hostgroup2 qui n’existent d’ailleurs pas ne devraient pas rendre de critical car ils ne sont pas pris en charge.Il vous faudra ajouter un worker avec la ligne :
Hostgroups=hostgroup2-servers
On peut évidemment mettre plusieurs workers pour un seul hostgroup, il suffit de les mettre avec la même configuration.
Worker Raspberry Pi Mod. B
Ce que je trouve magique avec l’architecture distribuée Gearman , c’est qu’elle peut être utilisée avec des Raspberry… Si vous ne connaissez pas, vous devriez vraiment vous pencher sur ces machines merveilleuses !
Pour réaliser un worker sur un raspberry PI mod.B , rien de plus simple. Une fois l’installation du Raspbian faite sur votre carte SD, lancez votre raspberry, configurez le avec le raspi-config, et ensuite mettez le à jour . (apt-get update , apt-get upgrade)
Ensuite, on tape :
apt-get install mod-gearman-worker
Il va s’installer, et vous n’aurez qu’à le configurer basiquement pour qu’il soit pris en charge
Exemple de config : /etc/mod-gearman-worker/worker.conf
server=ippublique:4730
key= Superpasswordquidéchire
hostgroup=hostgroup2-servers
encryption=yes
job_timeout=60
p1_file=/usr/share/mod-gearman/mod_gearman_p1.pl
Ouais… C’est tout!
Par défaut il va gérer le worker comme un petit chef, rien besoin de plus que ceci.
Le serveur, le password, le(s) hostgroup(s) , l’encryption, et par contre…
SURTOUT spécifier ce job_timeout=60 (60 ou ce qui conviendra à vos check, si vous avez par ex. un check qui met 2Mn à rendre son résultat, montez la valeur)
Si vous ne le faites pas et qu’un check « casse » en route, suite à un souci de connexion ou autre, votre worker attendra vita aeternam le résultat , et sera par conséquent… Planté ! ça ne vous ferait pas plaisir de faire 200Km en voiture pour débrancher et rebrancher un pc grand comme une carte de crédit, pas vrai ? (Comment ça, ça sent le vécu ? Je ne vous perm… oui c’est vrai.)
Donc , créez une machine virtuelle ou autre, sur une range inaccessible par votre serveur Nagios, avec l’ip spécifiée dans le fichier de config, (192.168.1.200) configurez la pour qu’elle réponde au ping et au ssh. Ensuite branchez un worker configuré comme expliqué sur le réseau ou elle se trouve… (en respectant la config d’ip selon le fichier de config dans nagios bien sûr)
Et comme par magie les deux machines seront prises en charge, de part leur configuration , le worker va contacter le job server, lui signaler sa présence, et là il enverra des tâches de check au worker qui les éxécutera et renverra le résultat au job server qui lui-même répondra à Nagios.
Surveillance des jobs
Je vous vois venir, vous pensez : « Mais comment est-ce que je vois ce qui se passe derrière tout ça ?
Et bien il y a une solution toute faite : gearman_top !
Il se trouve dans /opt/bin/
On peut ajouter son path dans la variable path en ajoutant :
PATH=$PATH:/opt/bin
Dans le fichier /root/.bashrc
Comme ça, vous pourrez le lancer comme n’importe quelle commande.
Lancez le , et admirez :
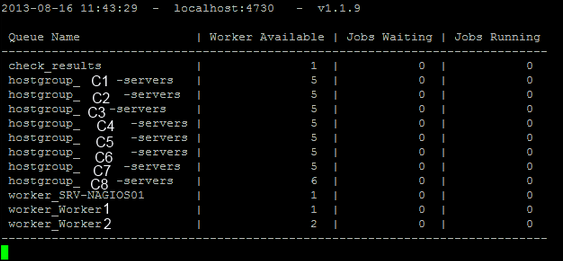
Voici une petite illustration d’une infrastructure avec 8 hostgroups , et des workers.
J’ai mis un serveur qui en gère 6 à lui seul , et 2 workers qui en gèrent un chacun.
J’ai utilisé des noms de clients donc je les ai censurés pour cet exemple.
Performances
Mod-gearman améliore énormément les performances de Nagios !
Même si vous ne comptez ni utiliser le distributed monitoring, ni le load balancing, ou le fail over, le choix d’utiliser mod-gearman sur votre nagios améliorera très nettement (on parle là de la moitié de consommation processeur, mesdammes !) les performances du serveur Nagios.
Pour les cas testés, et pas uniquement par moi, les gains de performances sont de pratiquement 50%
Tests réalisés sur des serveurs qui ont une utilisation moyenne de 55-60% de processeur, le fait de juste passer sur Gearman fait chuter la consommation processeur vers les 25%.
Mod-gearman EST un must, chers amis !
Problèmes rencontrés
Voici une petite liste des problèmes que j’ai rencontré en démarrant seul sans aucune info sur mod-gearman , le jour ou j’ai décidé de me pencher sur cette technologie et d’apprendre a partir de rien à m’en servir.
Timeout sur workers :
Au début je n’avais pas défini de temps de timeout sur les workers… ça m’a vallu un déplacement aussi long qu’inutile pour aller reboot le raspberry pi, n’oubliez pas de définir le job_timeout= sur vos workers…
Compilation gearman :
En temps normal je me contente de faire apt-get install lorsque j’ai besoin de quelque chose.
Or quand j’ai commencé à me servir de mod-gearman, les packages n’étaient pas disponibles en repo pour l’apt-get install… donc j’ai du me mettre à le compiler moi-même , d’où la procédure ou on voit sa compilation alors que des versions (évidemment pas aussi à jour que celle expliquée ici, au jour ou j’écris ceci) sont disponible en repo…
Je n’ai certainement pas réalisé le sans fautes, probable que certains packages dans la phase d’installation des paquets ne sont pas essentiels, mais j’ai trié au maximum et je pense avoir fait ça proprement. Je suis preneur pour toute suggestion ou remarque
Plantage gearmand au lancement :
Comme je le décris dans la procédure, il y a un plantage qui peut survenir au lancement de gearmand , qui se corrige par une modification du fichier dans /etc/init.d , ce problème m’a fait perdre pas loin d’une semaine, en ayant retourné le problème dans TOUS les sens , j’étais loin de suspecter qu’une option de verbosité, normalement présente pour aider a la résolution de problèmes de pantages, soit la cause du problème que je traquais… Comme quoi, il faut se méfier de tout.
Surveillance des workers
Je conclus cette rubrique par ce point, la surveillance de vos workers.
Si vous avez bien compris le fonctionnement des workers, on peut déceler une faille…
Si un worker n’est plus accessible, comment va-t-il répondre au job server pour dire qu’il n’est pas accessible ? On est d’accord c’est impossible. Alors, comment déterminer si un worker est OOR (out of range) ou non ?
J’ai pondu un petit script utilisant gearman_top qui permet ça. Le voici :
Le script:
#!/bin/bash
basevalue=`/opt/bin/gearman_top -b | grep "hostgroup_$1-servers"`
value1=`echo $basevalue | cut -d "|" -f3 | tr -d ' '`
value2=`echo $basevalue | cut -d "|" -f4 | tr -d ' '`
value3=`echo $basevalue | cut -d "|" -f2 | tr -d ' '`
critical=$2
threshold=$(($2/2))
if [[ $value1 -gt $critical ]]
then if [[ $value2 -gt $threshold ]]
then
echo " Accumulation de Jobs sur le worker $1, attention!"
echo " $value1 jobs en attente , $value2 jobs en cours "
retval=1;
else
echo " Le worker $1 ne prend plus de Jobs, Critical! "
echo " $value1 jobs en attente!"
retval=2;
fi
else
echo "Tout va bien. $value1 Wait $value2 run $value3 avail"
echo "$value1 jobs en attente, $value2 jobs en cours et $value3 workers dispo."
retval=0;
fi
exit $retval;
le fichier de definition de commande:
define command{
command_name check_workers
command_line /usr/lib/nagios/plugins/check_workers.sh $ARG1$ $ARG2$
}
Et un exemple utilisé sur mon serveur :
define service{
use generic-service
host_name ALTAIR-SRV-NAGIOS01
service_description Worker Altair
check_command check_workers!altair!15
}
Ma société veut que les jobs en attente, en exécution et les workers prêts à traiter pour le hostgroup altair me soit rendus, et dans le script , j’éxécute gearman_top avec l’option –b qui ne rend qu’une réponse, et utilisable en script, je trie avec un grep pour obtenir le nom qui m’intéresse, et ensuite je décortique les chiffres, et définis selon le nombre de jobs waiting que je veux d’avoir une alerte s’ils atteignent ce seuil, avec une petite sécurité toutefois, s’il y a une accumulation de checks pour une raison , peu importe laquelle, mais que mon worker travaille, je ne veux pas recevoir d’alerte. Je le laisse bosser…