Pour la sortie de Shinken 1.2, Jean Gabes a eu la gentillesse de répondre à quelques questions que je me posais sur cette nouvelle monture.
Pour la sortie de Shinken 1.2, Jean Gabes a eu la gentillesse de répondre à quelques questions que je me posais sur cette nouvelle monture.
Salut Jean et tout d’abord merci de nous consacrer un peu de ton temps.
Mais c’est bien normal !
C’est un été plutôt chargé pour toi avec la finalisation de la version 1.2 de Shinken et la rédaction du numéro spécial du GNU Linux Magazine. Comment arrives-tu à gérer cela en parallèle de tes activités professionnelles ?
Ce n’est pas simple, et ça l’est de moins en moins en fait. Avec le recul, même si la rédaction du hors série a pris du temps, c’est surtout la gestion du projet qui est la plus consommatrice en ce qui me concerne. Il y a de plus en plus d’intérêts pour le projet, ce qui est bien, et avec eux de plus en plus de contributeurs, ce qui est encore mieux.
Mais ceci à un coût en terme de temps de gestion, pour faire le “portier“ sur les patchs proposés, et demander (gentiment) par exemple, de revoir ce qui est proposé. Les forums sont de plus en plus actifs, heureusement, on a de plus en plus d’utilisateurs de la première heure qui prennent part au support sur le forum, et c’est une grande aide que j’apprécie vraiment.
Vue la progression de l’activité, je ne pourrais pas rester 100% administrateur et suivre le rythme, je vais devoir faire des choix pas très simples prochainement.
A titre personnel, je trouve que la principale évolution de cette version est apportée par le module de configuration (découverte automatique, gestion par “packs” et SKonf). Peux-tu nous en dire plus sur ce que cela va apporter aux utilisateurs ?
C’est également mon avis. Si l’on regarde bien, au tout début le projet était orienté pour les “power users” de Nagios, avec des modes distribués, plus de performances, des améliorations qui portent sur les très gros environnements. Je pensais que seuls ces utilisateurs avaient de gros soucis. Or ce n’est pas le cas.
Un peu dans la même philosophie que l’interface de visualisation “simple” WebUI, cette nouvelle interface de configuration est une réponse pour la majorité des administrateurs. Même si certains ne lâcheront pas leur sed, vi ou emacs, d’autres seront râvis de pouvoir ajouter dans la supervision une nouvelle machine en quelques secondes, avec des “tags” automatiques comme “Linux”, “Mysql” ou “DMZ”.
Cette tâche était si ingrate et complexe avec les anciens outils de configuration qu’elle était laissée à l’administrateur de la supervision (par exemple moi dans la société où je travaille…). Désormais tout le monde va pouvoir le faire très simplement et en quelques secondes. C’est un peu emprunté de l’esprit DevOps : l’administrateur de supervision va pouvoir définir des “règles” qui vont permettre de tagguer ses machines (par exemple : port 80 ouvert? -> tag http) et d’associer des services à ces tags (tag http? on lance la commande check_http). Les autres administrateurs vont désormais pouvoir ajouter “simplement” leurs hôtes sans avoir à se soucier des (nombreux!) paramètres de supervision, ni même savoir ce qu’est une sonde de supervision.
Un but avoué de l’outil est de ne plus avoir à s’occuper de notions de “services”. Seuls les hôtes et les templates d’hôtes (nos tags) sont importants dans la vie de tous les jours (demander à un administrateur système ce qu’il retient des notions d’hôtes et services Nagios, vous verrez qu’il aura beaucoup de mal au début avec les services, alors que pour l’hôte ce sera immédiat). Le but est donc de rentrer sa liste d’hôte, avec leurs propriétés (liste des volumes disques par exemple), et c’est tout…
Vu que l’outil se base sur la librairie de découverte, ce mode de fonctionnement peut être automatisé, comme par exemple “rescanner” des hôtes rajoutés précédement pour mettre à jour leur liste de volume disques, voir l’intégrer à un workflow automatique de création de machine virtuelle.
Les Packs sont également issus d’un constat que dans le microsome “Nagios” le partage de sondes est central, mais il n’en est rien de la bonne manière de les mettre en place et les utiliser. Si on prend comme exemple la supervision d’un serveur MySQL distant, la plupart des utilisateurs vont s’orienter vers la sonde check_mysql_health.pl, il y a alors beaucoup de manières de la mettre en place, de gérer les comptes et mots de passes, les seuils, etc. De même, comment bien représenter ces informations sur des outils comme PNP4Nagios ou Graphite et avec quel template ?
Les “packs” Shinken sont là pour cela. Ils sont un “concentré de bonnes pratiques” dans un fichier zip. Basiquement ce sont des fichiers de configuration, des icônes et des templates pour les graphiques, il n’y a rien de complexe ou de magique là dedans. C’est juste que lorsque l’on débute dans la supervision ou que l’on a un nouveau système d’exploitation ou autre, il est tout de même plus simple de partir d’un exemple de supervision que d’une page blanche. Les packs sont là pour que l’expérience des uns serve également au reste de la communauté.
Je suis donc tout à fait d’accord sur le fait que la gestion de configuration est bien l’élément central de cette version, bien plus que la page “dashboard” par exemple. Ce point sera encore central un bon moment, car cela reste la problématique N°1 des administrateurs aujourd’hui.
Par rapport à la version 1.0, on sent une certaine maturitée lors de l’utilisation de l’interface graphique de Shinken (WebUI). Quelles sont pour toi les axes d’améliorations encore possible ?
Question intéressante. Si l’on met de côté la nouvelle page de “dashboard”, il n’y a pourtant pas eu de profonds changements dans la manière de montrer les informations. C’est justement tout ce qui fait la complexité des interfaces graphiques. Il y a bien sûr les concepts centraux comme mettre en avant les problèmes importants pour le métier (et non pas la myriade d’impacts), ou encore de baser les droits sur les attributions des notifications pour les contacts.
Mais le ressenti des utilisateurs est également question de “détails” de présentations. Les détails seront par exemple la position des boutons d’actions pour lancer des actions sur la page d’hôte ou de service. Or ce que je nommais “détail” lorsque j’ai débuté WebUI n’en sont pas, et la question est là pour le prouver. Ils sont primordiaux dans le ressenti de l’utilisateur, sur la qualité même de l’interface.

Outre quelques nouvelles pages et widgets, la prochaine version sera encore améliorée un peu partout en terme d’ergonomie, pour que son utilisation soit la plus “naturelle” possible, si tant est qu’utiliser un outil de supervision puisse être “naturel” pour les utilisateurs. Disons qu’elle doit être là pour apporter le plus d’efficacité possible à ses utilisateurs, avec par exemple le fait d’avoir les boutons d’actions facilement utilisables sans que l’utilisateur ait besoin de les chercher un peu partout?
Quels sont les avantages apportés par les nouvelles fonctions de trigger par rapport aux classiques sondes ?
Pour rappel, les triggers sont du code Python fourni par l’utilisateur qui va être exécuté “en interne” de Shinken pour lire des états ou des données de performances d’hôtes et services puis pour ensuite lancer des actions, changer d’autres états ou créer des notifications.
C’est une très bonne question qui revient souvent dès que l’on a commencé à évoquer les triggers. Ils ne sont pas là pour remplacer les sondes de mesure de CPU ou d’espace disques, même si c’est techniquement possible. Dans 95% des cas de supervision, les bonnes vieilles sondes “à la Nagios” seront bien plus efficaces que les triggers, ne serait ce que du fait qu’il est facile des les tester (contrairement aux triggers).
Ils vont être utiles principalement pour deux choses :
- la corrélation avancée
- le traitement de données passives
Dans le premier cas, il est parfois utile d’agréger des informations en un seul indicateur. Par exemple si je veux présenter à mon responsable l’état du service mail fourni aux utilisateurs, je ne vais pas lui présenter la dizaine de serveurs et de services qui le composent. Je vais faire une règle “métier” avec des ET et des OU. Mais parfois ce genre d’opérateurs ne suffisent plus, et il faut sortir l’artillerie lourde qui compare des seuils les uns avec les autres pour savoir à quel point la situation est grave pour les utilisateurs. Ici les triggers vont permettre d’utiliser toute la puissance de Python pour “coder” une telle règle.
Dans le second cas, historiquement dans le monde Nagios, les commandes externes permettent de traiter des états envoyés par d’autres outils. Cependant, l’état doit déjà être calculé (comme OK ou CRITICAL). Il n’était pas possible d’importer une information et de l’analyser (comme par exemple un texte d’une TRAP SNMP). Désormais, des outils tiers peuvent envoyer des informations, la “vérification” sera alors faite en interne par Shinken.
Ce qui est intéressant lorsque l’on mélange les deux cas d’utilisation c’est que l’on obtient la définition de certains de l’Hypervision (en gros absorber des données d’outils de supervision, les traiter, les normaliser et en faire des états agrégés). Le plus drole c’est que le code qu’il a fallu pour ajouter les triggers au code de Shinken est ridiculement petit.
L’ouverture de Shinken vers des données recueillies par Collectd est très intéressante. N’as-tu pas peur de multiplier ainsi les interfaces et de complexifier l’administration ?
Dans le cas de Collectd, si ça alourdi la charge de développement, je ne pense pas que ceci ajoute une charge pour l’utilisateur. Il pourra choisir sa méthode de collecte de donnée favorite, et n’aura pas à utiliser les deux. Ce module était plus pour démontrer ce qu’il est possible de faire avec les triggers que pour remplacer les sondes classiques de supervision. Je ne pense pas que collecter les données de performances toutes les 10 secondes soit utile, donc je pense que beaucoup ne vont pas aller regarder du côté de Collectd, et vont se simplifier la vie en restant avec de la supervision “active”.
Le principe est cependant valable pour tout le reste du projet, et on tente d’avoir des fonctionalités le plus “ortogonales” possibles, donc qui ne se recoupent pas. Certains souhaitaient par exemple ajouter dans la configuration par défaut un “pack” linux basé sur le plugin check_by_ssh en plus de celui basé sur SNMP. J’ai refusé une telle chose car la plupart des utilisateurs vont devoir faire un choix qui est loin d’être simple. J’ai déjà raconté le temps qu’il m’avait fallu pour configurer mon premier Nagios (1 semaine pleine pour avoir une configuration convenable !) et je ne souhaite pas que les débutants de 2012 aient à passer par un tel “bizutage”…
Avec la nouvelle procédure d’installation en une ligne de commande, tu sembles vouloir prendre soin de tes utilisateurs. La phase de configuration initiale du réseau est encore longue et relativement complexe, vas-tu proposer des outils pour les aider ?
Grâce au gros travail de David Guenault, l’installation est désormais triviale, et c’est déjà une énorme victoire !
Ensuite vient la phase de configuration qui se passe en deux étapes:
- identifier les types d’éléments que l’on a (linux, windows, mysql, mssql, exchange, etc etc) et pour chacun mettre en place des sondes de supervision
- lister ses machines, et les entrer dans l’outil avec les bons types pour qu’elles aient toutes la bonne supervision adaptée et complète (car les soucis viendront toujours de quelque chose que l’on a oublié de supervisé, c’est bien connu).
C’est justement dans cette optique que nous avons développé les “packs” de supervision et la librairie de découverte avec son interface sKonf. Dans un environnement “classique” (linux, windows, mssql, mysql, apache, oracle …), une fois l’installation effectuée, il reste à lancer un scan de son réseaux et à configurer les bons mot de passe pour que l’on ait une supervision “acceptable”. Il restera toujours une phase d’adaptation, mais là où bon nombres d’administrateurs auraient déjà abandonnés avec un Nagios, là ils auront leur premiers résultats, et pourront commencer leur processus d’amélioration continue avec la supervision.
On passe à quelques questions plus générales. Pourquoi avoir choisi la licence Affero GPL pour la diffusion de Shinken ?
Dans bon nombre d’entreprises, la supervision est externalisée à une société de service, sur un serveur fourni par cette entreprise. Avec uniquement la license GPL, les utilisateurs n’auraient pas eu accès aux sources de l’application qui les surveille. Grâce à l’Affero, ils peuvent en exiger les sources, donc même si cela a fâché certaines personnes comme l’auteur de Nagios, j’ai préféré mettre le maximum de droits dans les mains des utilisateurs.
En face de toi, tu as une concurrence qui dispose de gros moyens commerciaux, marketing et de support technique. Comment te positionnes tu par rapport aux clients professionnels qui peuvent s’inquièter de la péréniter de Shinken ?
Heureusement pour le projet Shinken l’effet “communauté” tourne à plein régime et nous n’avons pas à rougir de l’activitéque ce soit en nombres de commits ou de commiters !
Le marketing et l’aspect commercial sont cependant deux points faibles. Ce n’est peut être pas un hasard car si je regarde bien, ceci reflète bien mes propres points faibles…
Or (malheureusement?) la technique ne fait pas tout. Il est bien plus logique pour un décideur d’aller vers une solution bien vendue avec des “petits déjeuners”, de jolies tablettes de présentations et un discours marketing bien rodé, que de prendre des “risques” et partir vers une solution pleinement communautaire, même si elle réponds au besoin.
La seule solution est de monter une structure professionnelle derrière le projet qui permette de rassurer les décideurs avec du support et une assurance de la perénité des produits. Or c’est bien plus complexe que l’on pourrait le croire, car monter un business dans le monde Open Source d’un point de vue “éditeur” est très difficile lorsque l’on se rapproche de la technique comme ici (même si voir la supervision comme de la pure technique est une erreur qui mène un projet de supervision à sa perte soit-dit en passant).
On a l’habitude de dire que la solution vient des “services”, surtout de l’intégration quand on écoute bien. Mais si l’on souhaite monter un pur “éditeur”, là la relation intégrateur-éditeur est très vite déséquilibrée pour l’éditeur, avec des intégrateurs qui vont vendre un pack de support complet avec leur intégration. L’éditeur n’a donc plus que la ressource de développement à la demande, quand ce n’est pas un intégrateur qui s’en occupe 🙂
Une solution simple serait de faire comme l’auteur de Nagios ou d’autres éditeur de supervision “open source” en proposant une surcouche graphique ou des modules sous licenses proprietaires et payantes. Si je comprends parfaitement comment ils en sont arrivés à une telle position, je n’ai pas envie de tomber dans le même piège. Je préfèrerai encore rester un simple administrateur de campagne que de faire de même 🙂
La problématique est complexe, car monter une société n’est pas déjà pas simple, mais quand c’est monter une offre “éditeur” dans ce domaine, c’est carément un défi ! Heureusement les mentalités commencent à bouger, et le projet d’entreprise Shinken est par exemple lauréat du concours de création d’entreprise innovante 2012 du ministère de la recherche!
D’autres solutions existent, comme par exemple monter une offre SaaS, ou la gestion à la RedHat avec un projet communautaire (fedora) et une version toujours libre (RedHat 6 par exemple) mais supportée quelques années. Trouver la solution idéale est l’activité qui occupe le peu de temps libre que j’ai encore. J’avoue que pouvoir travailler à 100% sur Shinken m’intéresse plus que fortement (ndlr: avis aux sponsors !)
Pour finir cette interview, peux-tu nous donner, en avant première mondiale, une ou deux nouveautées que tu souhaites intégrer dans la prochaine version de Shinken ?
La curiosité est un très bon défaut 🙂
Outre un gros effort pour “finir” sKonf (par exemple le fait qu’il puisse relancer Shinken serait intéressant….), il va y avoir de nouvelles pages dans WebUI, sur la supervision “End user” à la Cucumber, et une autre sur de la géolocalisation. Les plus curieux peuvent déjà en voir les premières versions déjà présentes dans le code 🙂
Plus proche du coeur de l’outil, une problématique me taraude l’esprit depuis quelques temps : comment changer ses seuils de supervision pendant certaines périodes de temps, genre augmenter les valeurs critique de charge pendant les backups? Un des membres du projet (Olivier Hanesse) a proposé une solution particulièrement élégante qui me plais tellement que je pense qu’elle va arriver très rapidement.
Un petit mot pour finir ?
J’aimerais remercier tous ceux qui font vivre le projet, que ce soit avec des remontées de bugs, des patchs, de la documentation ou même un petit merci par mail, car sans eux un projet ne pourrait pas tenir aussi longtemps et se serait sûrement arrété à la phase de la preuve de concept, il y a près de 3 ans.
S’il y en a qui souhaitent prendre part à cette belle aventure, qu’ils n’hésitent pas à me contacter !

 Je viens de lire le mail d’un lecteur concernant ses interrogations sur le choix des logiciels permettant de surveiller son réseau. Comme c’est une question récurrente dans ma boîte mail et que je pense que ses questions et nos réponses peuvent intéresser d’autres personnes, j’ai décidé de lui répondre directement sur le blog.
Je viens de lire le mail d’un lecteur concernant ses interrogations sur le choix des logiciels permettant de surveiller son réseau. Comme c’est une question récurrente dans ma boîte mail et que je pense que ses questions et nos réponses peuvent intéresser d’autres personnes, j’ai décidé de lui répondre directement sur le blog.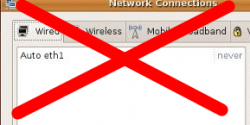
 S’il y a bien une fonction que je trouve mal faite dans Gnome c’est le « Network Manager ». Ce logiciel, accessible depuis la barre de menu, permet de configurer, à partir d’une interface graphique, les interfaces réseaux de sa machine. Ce n’est pas la première fois que je tombe sur une configuration que je n’arrive pas à appliquer en utilisant ce logiciel. Il faut dire que celle-ci mélange plusieurs interfaces réseaux avec des configurations DHCP, statiques et des routes spécifiques. J’ai donc décidé de désactiver Network Manager et de configurer mon réseau à la mimine.
S’il y a bien une fonction que je trouve mal faite dans Gnome c’est le « Network Manager ». Ce logiciel, accessible depuis la barre de menu, permet de configurer, à partir d’une interface graphique, les interfaces réseaux de sa machine. Ce n’est pas la première fois que je tombe sur une configuration que je n’arrive pas à appliquer en utilisant ce logiciel. Il faut dire que celle-ci mélange plusieurs interfaces réseaux avec des configurations DHCP, statiques et des routes spécifiques. J’ai donc décidé de désactiver Network Manager et de configurer mon réseau à la mimine.