Depuis février 2014, Olivier Jan et son équipe ont lancé un service en ligne permettant de surveiller ses sites Web et d’être alerté uniquement en cas de problème. Cette supervision minimaliste répond à un besoin croissant dans les infrastructures informatique actuelles: contrôler le ressenti utilisateur plutôt que les indicateurs techniques. En plus, la solution technique qui se cache derrière le site Check my Website se base sur des solutions open-source largement partagés sur le blog officiel qui est une source d’information que je vous conseille de suivre.
Pour quels besoins ?
Check my Website a pour objectif de surveiller, à travers le temps, la disponibilité, le temps de réponse et la conformité aux standards de performances du Web de vos sites Internet. En cas de problème, on peut être alerté par mail ou SMS. Une console, que nous présenterons plus loin dans cet article, permet de visualiser, sous la forme de courbes et de tableau, l’ensemble des indicateurs.
Il ne nécessite aucune installation sur votre site Web, que cela soit sur le serveur ou même dans les pages de votre site. Il construit ses statistiques en utilisant des requêtes HTTP. Ce n’est donc pas une solution de supervision classique. On ne pourra pas, par exemple, connaître le taux d’occupation mémoire ou la charge CPU du serveur hébergeant votre site.
Le tour du propriétaire
La mise en route de la supervision de votre site ne prend pas plus de 5 minutes. Il suffit de s’inscrire sur le site et de déclarer l’adresse du site à surveiller. Une période d’essai gratuite de 15 jours est proposée. Il faudra ensuite choisir votre forfait en fonction du nombre de site à surveiller et des fonctions proposées. Par exemple, pour un site, le ticket d’entrée est de 16€ par an (tarif au 10 juin 2015).
A noter que Check my Website propose un service ‘Free for FOSS » entièrement gratuit pour les sites de projets Open Source et/ou associatifs (voir les condition sur le site) !

Une fois les sites déclarés, les statistiques arrivent sur la console. On commence par la vue générale offrant une vue d’ensemble de vos sites:

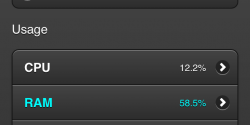
Pour chaque site, on a un tableau de bord qui résumant les indicateurs critiques:

On peut ensuite faire un focus sur un site en particulier pour consulter les statistiques (menu metrics):
- temps de réponse
- disponibilté
- temps de chargement total de la page

Il est bien sûr possible de zoomer sur les courbes et de revenir sur des périodes passées:


Dans l’onglet performance, on retrouve des informations et conseils pouvant vous permettre d’améliorer l’expérience utilisateur des visiteurs de votre site.

Enfin, en cas de problème, il est possible d’entrée dans le détail du temps de chargement de votre site:

Mon impression
J’ai eu la chance de tester gratuitement le service pendant plusieurs semaines sur 3 de mes sites personnels (notamment le blog que vous êtes en train de lire). Check my Website « fait le job ». L’interface utilisateur est simple et intuitive. Il se fait oublier, alerte en cas de problème et il alors facile d’identifier la période d’indisponibilité ou de baisse de performance. Il peut aussi être très utile dans les phases de migration (lors d’un changement d’hébergeur ou d’un thème) pour juger du maintient des performances.
Il manque cependant à mon goût des statistiques internes (CPU, RAM, occupation disque, état des services de la stack web…) mais qui ne peuvent pas être mis en place sans l’installation d’un composant ou d’une configuration côté serveur.
Pour conclure, c’est un service que je conseille à toutes les personnes possédant un site Web sensible et qui ne veulent pas s’embêter avec la mise en place d’une solution de supervision type Nagios ou Shinken.Il serait d’ailleurs sympa que le service soit proposé en option par les hébergeurs (cc: Online.fr, OVH, Web4All…).