
Il y a quelques jours, un billet sur le blog officiel de GitHub a particulièrement attiré mon attention. Pour faire court, GitHub vient de supprimer le « Tab Download » qui proposait un moyen simple d’héberger le téléchargement des sources/binaires en dehors du gestion de configurationen version. J’utilisais cette solution pour héberger les archives des différentes versions de Glances que j’utilisais dans mon script d’installation setup.py.
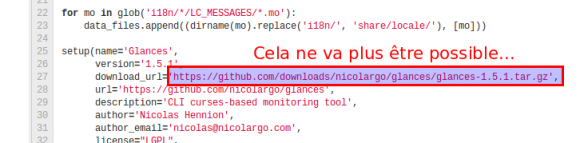
J’ai donc du trouver une solution alternative pour héberger ces fichiers. Trois solutions se présentaient à moi:
- Utiliser le « Tab Tag » de Github dans lequel est automatiquement généré les versions tagués (au sens Git). J’ai rapidement écarté cette solution car j’ai besoin d’un système plus souple (pour héberger par exemple des versions bêta, non taguées) et ouvert (par exemple pour héberger les futures binaires pour Glances Windows).
- Héberger ces fichiers sur mon serveur dédié. C’est la solution la plus logique mais qui ne présente pas, à mon goût, assez de robustesse. En effet, en cas de panne/problème de mon serveur (ou de l’hébergeur) je souhaite que les utilisateurs puissent continuer à mettre à jour ou installer Glances.
- Utiliser un service en ligne fait pour cela comme Amazon Simple Storage Service (Amazon S3 pour les intimes).
C’est donc sur cette dernière solution que je suis parti.
Amazon S3 ? C’est quoi donc ?
C’est un service dans « les nuages » permettant de stocker des objets (répertoires, fichiers) dans des buckets (librairies). On peut ensuite accéder à nos objet via une simple URL (par exemple: https://s3.amazonaws.com/glances/glances-1.5.1.tar.gz).
Il est payant mais relativement peu coûteux pour l’hébergement de petits fichiers (voir la grille tarifaire ici et le détail de l’offre là).
J’ai donc commencé par créer un compte puis par tester le stockage de mes premiers fichiers à partir de la console en ligne proposée par Amazon.
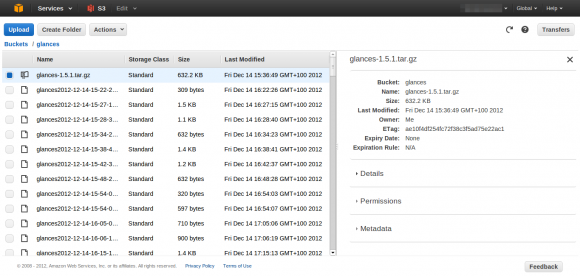
Comme la plupart des interfaces de ce type, elle est très simple à utiliser mais montre ces limites quand on souhaite automatiser les taches comme par exemple publier par script un nouveau fichier dans une librairie.
s3cmd, le couteau suisse de Amazon S3
Heureusement, la ligne de commande vient à notre secours grâce au logiciel open-source s3cmd.
On commence par installer s3cmd sur notre système GNU/Linux (Debian / Ubuntu):
sudo apt-get install s3cmd
Puis on effectue la configuration initiale qui va permettre de donner les autorisation nécessaire à votre machine pour accéder à votre espace S3. Pour cela, nous avons besoins des clés publique (1) et privé (2) de notre compte Amazon AWS (via cette page):
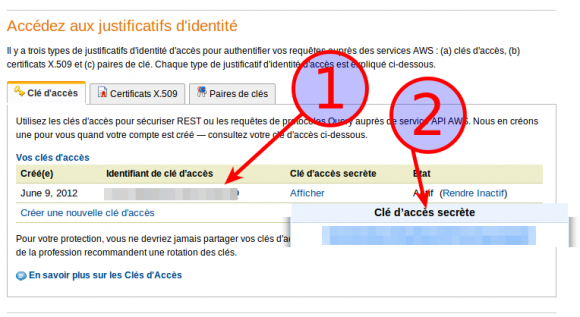
… de saisir la commande suivante:
s3cmd --configure
et de se laisser guider…
Une fois cette commande terminé, vous devriez pouvoir accéder à votre compte Amazon S3 depuis la ligne de commande de votre machine.
Guide d’utilisation de s3cmd
Créer un bucket (mb)
Un bucket est le conteneur de plus haut niveau dans la terminologie d’Amazon S3. On peut le voir comme un disque dur dédié ou comme une librairie. Dans mon cas précis, j’ai donc commencé par créer le bucket glances en utilisant la commande suivante:
s3cmd mb s3://glances
Affiche la liste de vos buckets
On peut vérifier que l’opération c’est bien passée en affichant la liste des buckets disponibles:
s3cmd ls 2012-12-14 14:35 s3://glances
Ajouter un nouveau fichier (objet) dans un bucket
On peut ensuite ajouter un objet de type fichier dans ce bucket.
Par défaut, un objet est privé (donc seulement accessible avec les clés privée et publique de votre compte).
s3cmd put glances-1.5.1.tar.gz s3://glances/glances-1.5.1.tar.gz
Pour créer le même objet mais de manière publique (donc accessible depuis une URL), on doit saisir:
s3cmd put --acl-public --guess-mime-type glances-1.5.1.tar.gz s3://glances/glances-1.5.1.tar.gz
Afficher le contenu d’un bucket
Pour afficher le contenu d’un bucket:
s3cmd ls s3://glances 2012-12-14 14:36 647418 s3://glances/glances-1.5.1.tar.gz
Comment télécharger ces objets ?
Pour télécharger un fichier depuis un bucket, on peut soit directement utiliser son URL publique (pour les objets publics) : https://s3.amazonaws.com/glances/glances-1.5.1.tar.gz
ou en ligne de commande (pour tous les objets):
s3cmd get s3://glances/glances-1.5.1.tar.gz glances-1.5.1.tar.gz
Supprimer un fichier dans un bucket
On doit saisir la ligne de commande:
s3cmd del s3://glances/glances-1.5.1.tar.gz
Supprimer un bucket
Un bucket doit être vide avant d’être supprimé par la commande:
s3cmd rb s3://glances
Synchronisation
Si vous souhaitez, avec s3cmd, gérer des structures de données plus complexes sur votre espace Amazon S3, il est également possible d’utiliser les fonctions de synchronisation (voir la documentation ici).
Mot de fin
Pour finir j’ai donc modifié mon script de génération de nouvelle version de Glances pour automatiser l’upload vers Amazon S3 et aussi changé mon script setup.py de cette façon:

Et vous ? Que pensez-vous d’Amazon S3 ? Utlisateur ? Avec s3cmd ?