D’abord orienté vers la supervision de machines distantes, Glances permet également de surveiller l’ensemble des paramètres systèmes de ses machines bureautique. De plus, depuis sa version 1.7.2 , Glances offre une interface Curses sur l’ensembles des plateformes: GNU/Linux, BSD, Mac OS et même … MS Windows.
Il est en effet fréquent d’observer un ralentissement, voir un blocage de sa machine locale. Nous allons voir comment configurer puis utiliser Glances pour en trouver les causes et ainsi prendre les actions adéquates.
Configuration de Glances
Après installation de Glances sur son système (le plus simple étant de passer par PyPI), un fichier de configuration par défaut est disponible sous /etc/glances/glances.conf sous GNU/Linux (voir ici pour les emplacements sur les autres systèmes). Je vous conseille de copier ce fichier en local dans votre répertoire de configuration standard (~/.config/glances ou $XDG_CONFIG_HOME/glances).
mkdir -p ~/.config/glances cp /etc/glances/glances.conf ~/.config/glances/
On peut ensuite éditer son fichier selon ses besoins: ~/.config/glances/glances.conf
Voici le fichier que j’utilise sur mon PC portable:
[cpu] # Limits values for CPU user in % # Defaults values if not defined: 50/70/90 user_careful=50 user_warning=70 user_critical=90 # Limits values for CPU system in % # Defaults values if not defined: 50/70/90 system_careful=50 system_warning=70 system_critical=90 # Limits values for CPU iowait in % # Defaults values if not defined: 40/60/80 # Not easy to tweek... # Source: http://blog.scoutapp.com/articles/2011/02/10/understanding-disk-i-o-when-should-you-be-worried # http://blog.logicmonitor.com/2011/04/20/troubleshooting-server-performance-and-application-monitoring-a-real-example/ # http://blog.developpeur-neurasthenique.fr/auto-hebergement-iowait-ma-tuer-1-2-vmstat-mpstat-atop-pidstat.html (FR) iowait_careful=40 iowait_warning=60 iowait_critical=80 [load] # Value * Core # Defaults values if not defined: 0.7/1.0/5.0 per Core # Source: http://blog.scoutapp.com/articles/2009/07/31/understanding-load-averages # http://www.linuxjournal.com/article/9001 careful=0.7 warning=1.0 critical=5.0 [memory] # Defaults limits for free RAM memory in % # Defaults values if not defined: 50/70/90 careful=50 warning=70 critical=90 [swap] # Defaults limits for free swap memory in % # Defaults values if not defined: 50/70/90 careful=50 warning=70 critical=90 [temperature] # Temperatures in °C for sensors # Defaults values if not defined: 60/70/80 careful=60 warning=70 critical=80 [hddtemperature] # Temperatures in °C for hddtemp # Defaults values if not defined: 45/52/60 careful=45 warning=52 critical=60 [filesystem] # Defaults limits for free filesytem space in % # Defaults values if not defined: 50/70/90 careful=50 warning=70 critical=90 [process] # Limits values for CPU per process in % # Defaults values if not defined: 50/70/90 cpu_careful=50 cpu_warning=70 cpu_critical=90 # Limits values for MEM per process in % # Defaults values if not defined: 50/70/90 mem_careful=50 mem_warning=70 mem_critical=90 [monitor] # Define the list of processes to monitor # *** This section is optionnal *** # The list is composed of item (list_#nb <= 10) # An item is defined: # * description: Description of the processes (max 16 chars) # * regex: regular expression of the processes to monitor # * command: (optional) full path to shell command/script for extended stat # Use with caution. Should return a single line string. # * countmin: (optional) minimal number of processes # A warning will be displayed if number of process < count # * countmax: (optional) maximum number of processes # A warning will be displayed if number of process > count list_1_description=Chromium browser list_1_regex=.*chromium-browse.* list_1_countmax=50 list_2_description=OpenVPN list_2_regex=.*openvpn.* list_2_countmin=1 list_3_description=Dropbox list_3_regex=.*dropbox.* list_3_countmin=1 list_3_command=dropbox filestatus ~/Dropbox
En plus des jeux de limites pour les alertes de CPU, de charge (LOAD) et de mémoire (MEM), je souhaiterai que l’on s’attarde un peu sur la section [monitor] qui permet de mettre en avant une liste de processus jugés importants.
[monitor] # Define the list of processes to monitor # *** This section is optionnal *** # The list is composed of item (list_#nb <= 10) # An item is defined: # * description: Description of the processes (max 16 chars) # * regex: regular expression of the processes to monitor # * command: (optional) full path to shell command/script for extended stat # Use with caution. Should return a single line string. # * countmin: (optional) minimal number of processes # A warning will be displayed if number of process < count # * countmax: (optional) maximum number of processes # A warning will be displayed if number of process > count list_1_description=Chromium browser list_1_regex=.*chromium-browse.* list_1_countmax=50 list_2_description=OpenVPN list_2_regex=.*openvpn.* list_2_min=1 list_3_description=Dropbox list_3_regex=.*dropbox.* list_3_countmin=1 list_3_command=dropbox filestatus ~/Dropbox
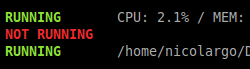
Je défini donc 3 groupes de processus qui vont donner l’affichage suivant dans l’interface de Glances:

Supervision de Chromium
Le premier groupe (list_1) permet de surveiller les processus relatifs à mon navigateur Web (Chromium).
Pour cela je lui donne un label (list_1_description) qui est une chaîne de caractères complètement arbitraire (mais limité à 15 caractères):
list_1_description=Chromium browser
Ensuite, il faut définir l’expression régulière qui va permettre de regrouper les processus:
list_1_regex=.*chromium-browse.*
Le problème avec Chromium, c’est qu’il peut être très consommateur de ressources (notamment mémoire) si l’on ouvre un grand nombre de pages. Je configure donc une surveillance du nombre maximum de processus. Glances affichera donc la ligne en rouge si ce nombre est dépassé:
list_1_countmax=50
Je ne défini pas de commande (list_1_command) associé à ce groupe. Donc par défaut Glances va calculer la consommation CPU et la mémoire globale des processus de ce groupe.
Supervision d’OpenVPN
J’utilise souvent un service VPN pour surfer (entre autre…) sur le Web. J’ai donc ajouté une supervision du processus OpenVPN:
list_2_description=OpenVPN list_2_regex=.*openvpn.* list_2_min=1
Contrairement à Chromium, je pose ici une alerte si le nombre de processus est inférieur à 1 (donc si OpenVPN n’est pas lancé).
Supervision de Dropbox
Avoir ces fichiers disponibles sur toutes ses machines est devenu pour moi complètement indispensable. La supervision du service Dropbox est faite par Glances de la manière suivante:
list_3_description=Dropbox list_3_regex=.*dropbox.* list_3_countmin=1 list_3_command=dropbox filestatus ~/Dropbox
Rien de bien nouveau sur les 3 première lignes, la dernière nécessite cependant quelques explications. La commande (shell) passée en paramètre de (list_3_command) sera exécuté à chaque « check » de Glances (donc par défaut toutes les 3 secondes). Cette commande va demander à Dropbox l’état de synchronisation mon répertoire (voir ce billet pour apprendre à administrer Dropbox en ligne de commande).
Utilisation de Glances
Votre Glances est maintenant prêt à être utilisé. Donc si vous rencontrez un problème sur votre machine, il faudra ouvrir un terminal et saisir la commande:
glances -ey -C ~/.config/glances/glances.conf
Glances va se lancer et afficher les informations sur votre système:

En plus de la section [monitor] ou l’on retrouve la supervision de nos groupes Chromium, OpenVPN et Dropbox, on a également l’ensemble des informations systèmes.
Dans le bandeau du haut, les informations sur la CPU, la charge et la mémoire. Les codes couleurs sont standards:
Sur le panneau de gauche, on a les informations moins critiques comme: les débits des interfaces réseau, les capteurs de température, les IO disques et l’espace disque.
Au centre, sur la section [monitor], on retrouve la liste des processus avec, par défaut, un tri « intelligent ». Par exemple, en cas de consommation mémoire excessive, le tri sera automatiquement fait sur la consommation RAM des processus.
Enfin en bas de l’écran, un rappel des dernières alertes.
Pour une description précise des fonctions de Glances, je vous conseille la lecture de la documentation officielle (lisible ici).
Conclusion
Nous arrivons à la fin de ce billet. Je n’ai pas parlé du mode client serveur qui permet de lancer Glances en tache de fond et de l’interroger à la demande mais je pense que ce mode d’utilisation est plus utilise pour la supervision de serveurs.
Si vous avez des configurations spécifiques de Glances (et surtout du [monitor]) pour surveiller vos PC, partager cela (configuration et screenshot) avec nous !

 Je viens de lire le mail d’un lecteur concernant ses interrogations sur le choix des logiciels permettant de surveiller son réseau. Comme c’est une question récurrente dans ma boîte mail et que je pense que ses questions et nos réponses peuvent intéresser d’autres personnes, j’ai décidé de lui répondre directement sur le blog.
Je viens de lire le mail d’un lecteur concernant ses interrogations sur le choix des logiciels permettant de surveiller son réseau. Comme c’est une question récurrente dans ma boîte mail et que je pense que ses questions et nos réponses peuvent intéresser d’autres personnes, j’ai décidé de lui répondre directement sur le blog.










