Il y a quelques jours, je vous avez présenté la première version de Glances, mon logiciel pour surveiller simplement ses systèmes en mode texte à partir d’une console ou d’un terminal. Quelques versions plus tard (Glances est actuellement disponible en version 1.3.7), il était temps pour moi de vous en faire une présentation un peu plus complète.
Introduction
Glances est un logiciel libre (distribué sous licence LGPL) permettant de surveiller votre système d’exploitation GNU/Linux ou BSD à partir d’une interface texte. Glances utilise la librairie libstatgrab pour récupérer les informations de votre système. Il est développé en langage Python.

Installation
Depuis le gestionnaire de paquet de votre système
Des paquets existent pour plusieurs distributions: Arch, Fedora/Redhat…
Le processus de packaging est actuellement en cours sur d’autres distribs, je vous conseille donc de rechercher Glances (avec un s !) sur votre gestionnaire de package avant de faire une installation depuis les sources.
Merci de laisser un commentaire dans ce billet si vous trouvez Glances sur votre système 🙂
Depuis le PPA
Pour les distributions Ubuntu (et dérivées) depuis la 9.10 jusqu’à la 12.04, il est possible d’utiliser le PPA généreusement maintenu par Arnaud Hartmann.
[cc lang=bash »]
sudo add-apt-repository ppa:arnaud-hartmann/glances-stable
sudo apt-get update
sudo apt-get install glances
[/cc]
Depuis les sources
Le projet Glances est hébergé sur GitHUB.
Pour l’installer, il suffit de suivre les instructions suivantes depuis un terminal.
Récupération de la dernière version (1.3.7):
[cc]
$ wget https://github.com/downloads/nicolargo/glances/glances-1.3.7.tar.gz
[/cc]
Procédez ensuite à l’installation:
[cc]
$ tar zxvf glances-1.3.7.tar.gz
$ cd glances-1.3.7
$ ./configure
$ make
$ sudo make install
[/cc]
Glances a besoin des dépendances suivantes:
- Python 2.6+ (non testé avec Python 3+)
- libstatgrab 0.16+
- python-statgrab 0.5+ (ne marchera PAS avec python-statgrab 0.4)
Notes specifiques pour une installation sous Debian 6.
Debian Squeeze met à disposition la version 0.4 de python-statgrab. Il faut donc installer la version 0.5 à la main:
[cc]
$ sudo apt-get install libstatgrab-dev pkg-config python-dev make
$ wget http://ftp.uk.i-scream.org/sites/ftp.i-scream.org/pub/i-scream/pystatgrab/pystatgrab-0.5.tar.gz
$ tar zxvf pystatgrab-0.5.tar.gz
$ cd pystatgrab-0.5/
$ ./setup.py build
$ sudo ./setup.py install
[/cc]
Notes specifiques pour une installation sous Ubuntu 10.04 et 10.10.
Ces versions d’Ubuntu mettent à disposition la version 0.4 de python-statgrab. Il faut donc installer la version 0.5 à la main:
[cc]
$ sudo apt-get update
$ sudo apt-get install pkg-config build-essential autoconf automake python libstatgrab-dev python-all-dev
$ sudo apt-get remove python-statgrab
$ wget http://ftp.uk.i-scream.org/sites/ftp.i-scream.org/pub/i-scream/pystatgrab/pystatgrab-0.5.tar.gz
$ tar zxvf pystatgrab-0.5.tar.gz
$ cd pystatgrab-0.5/
$ ./setup.py build
$ sudo ./setup.py install
[/cc]
Lancement de Glances
Il suffit de saisir la commande suivante dans une console ou un terminal:
[cc]
$ glances.py
[/cc]
Note: sur certaines distributions, il faut saisir glances en lieu et place de glances.py.
Guide d’utilisation
Par défaut, l’affichage des statistiques est rafraichi toute les secondes.
Il est possible de changer cette valeur en utilisant l’option -t. Par exemple pour fixer un taux de rafraichissement à 5 secondes:
[cc]
$ glances.py -t 5
[/cc]
Les statistiques jugées importantes sont affichées en couleur:
- VERT: la statistique est « OK »
- BLEU: la statistique est « CAREFUL » (à surveiller)
- VIOLET: la statistique est « WARNING » (en alerte)
- ROUGE: la statistique est « CRITICAL » (critique)
Quand Glances est lancé, il est possible d’utiliser les touches suivantes:
‘a‘ pour trier la liste des processus de manière automatique:
- Si la CPU totale > 70% alors le tri se fait pas consommation CPU
- si la mémoire total > 70% alors le tri se fait pas consommation MEMOIRE
‘c‘ pour forcer le tri par consommation CPU
‘d‘ pour desactiver ou activer l’affichage des entrées/sorties disques
‘f‘ pour desactiver ou activer l’affichage de l’occupation des FS
‘h‘ pour afficher ou cacher l’aide en ligne
‘m‘ pour forcer le tri par consommation MEMOIRE
‘n‘ pour desactiver ou activer l’affichage des interfaces réseau
‘q‘ pour quitter Glances (il est également possible d’utiliser CTRL-C)
Passons ensuite à la description de la fenêtre de Glances:
En-tête

L’en-tête montre la version de Glances, le nom de la machine (FQND) ainsi qu’une information sur le système d’exploitation (nom, version).
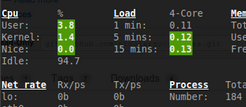
CPU

L’état de la CPU est affiché par un pourcentage de l’utilisation globale.
- Si user|kernel|nice CPU est < 50%, alors le status est « OK ».
- Si user|kernel|nice CPU est > 50%, alors le status est « CAREFUL ».
- Si user|kernel|nice CPU est > 70%, alors le status est « WARNING ».
- Si user|kernel|nice CPU est > 90%, alors le status est « CRITICAL ».
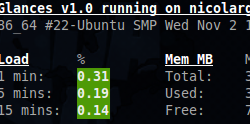
Charge moyenne (aka Average Load)

Il est assez difficile de donner une définition claire de la charge d’une machine (load average). Sur le blog Nosheep, Zach en donne la définition suivante:
» C’est la somme moyenne du nombre de processus en attente dans la queue d’execution plus le nombre de processus actuellement en train d’être executés sur une période de temps de 1, 5 et 15 minutes. »
Glances permet d’afficher les alertes en tenant compte du nombre de coeurs de votre processeur. Par exemple, le seuil WARNING sera de 2 pour un processeur Bi-Core alors qu’il sera de 4 sur un Quad-Core.
- Si la charge moyenne est < O.7*Core, alors le status est « OK ».
- Si la charge moyenne est > O.7*Core, alors le status est « CAREFUL ».
- Si la charge moyenne est > 1*Core, alors le status est « WARNING ».
- Si la charge moyenne est > 5*Core, alors le status est « CRITICAL ».
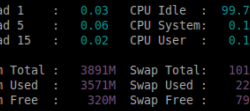
Mémoire

Glances affiche 3 types d’informations pour la mémoire: RAM, SWAP et réelle (un peu à la manière de la commande « free -h »).
La mémoire réelle occupée est calculée ainsi = used – cache.
La mémoire réelle libre est calculée ainsi = free + cache.
Les alertes utilisent les seuils suivants:
- Si la mémoire est < 50%, alors le status « OK ».
- Si la mémoire est > 50%, alors le status « CAREFUL ».
- Si la mémoire est > 70%, alors le status « WARNING ».
- Si la mémoire est > 90%, alors le status « CRITICAL ».
Débits des interfaces réseau

Glances affiche les débits des interfaces réseau en adaptant dynamiquement l’unité à utiliser (bits par seconde).
Les alertes ne sont affichées que pour les interfaces dont les informations sur la vitesse maximale sont disponibles (cela dépend des distributions):
- Si le débit < 50%, alors le status est « OK ».
- Si le débit > 50%, alors le status est « CAREFUL ».
- Si le débit > 70%, alors le status est « WARNING ».
- Si le débit > 90%, alors le status est « CRITICAL ».
Par exemple, sur une interface Ethernet Fast Ethernet (100 Mbps), le status passera à WARNING si le débit dépasse les 70 Mbps.
Entrées/Sorties disque

Glances permet d’afficher les débits en lecture et écriture sur les disques en adaptant dynamiquement l’unité à utiliser (octets par seconde).
Il n’y a pas d’alerte remontée pour ce type d’information.
Espace sur les systèmes de fichiers

Glances affiche par système de fichiers l’espace disque total et utilisé. L’unité est automatiquement adaptée (octets par seconde).
Les alertes sont remontées sur l’espace disque utilisé:
- Si l’espace disque utilisé est < 50%, alors le status est « OK ».
- Si l’espace disque utilisé est > 50%, alors le status est « CAREFUL ».
- Si l’espace disque utilisé est > 70%, alors le status est « WARNING ».
- Si l’espace disque utilisé est > 90%, alors le status est « CRITICAL ».
Les processus

Glances affiche un résumé sur l’état des processus ainsi qu’une liste détaillé (CPU, MEMOIRE et nom du processus).
Le nombre des processus affichés est adapté à la taille de la fenêtre.
Les logs
Nouveauté de la version 1.3.7.
Lire le billet suivant pour une description de la fonction logs.
Pied de page

Glances y affiche la légende (rappel des codes des couleurs) ainsi que la date et l’heure courante.
A faire…
J’ai besoin de contributeurs pour faire évoluer Glances.
Notamment:
- Packaging pour Debian, Ubuntu, BSD et toutes autres distributions
- Controle de la présence des librairie dans le fichier configure.ac
- Inclure les stats de FS directement dans python-statgrab
- Ajout d’une fenêtre d’aide
- Optimisation du code
Pour toutes remarques, bugs, demande d’évolution sur Glances, merci d’utiliser le formulaire GitHub.