
Avec le temps, je suis devenu un grand adepte de Munin, le logiciel de supervision permettant de centraliser la gestion des graphes de données RRDTools.
Sa simplicité de prise en main et d’administration y est pour beaucoup. En effet, en une ligne de commande il est possible d’analyser une nouvelle machine à superviser. Munin va s’occuper de générer automatiquement tous les graphes possibles et imaginables. Cette simplicité est notamment dû à l’architecture client/serveur de Munin qui masque en grande parti la complexité des mécanismes de récupération de données à grapher.
Pour superviser un hôte comme des équipements réseaux (routeur Cisco, Switch…) ou des appliances (NAS…) sur lesquels il est impossible d’installer le client Munin, il faut passer par une configuration spécifique au niveau du serveur, utilisant le protocole SNMP, que nous allons détailler dans ce billet.
Comment ça marche ?
Contrairement au fonctionnement nominal de Munin, le serveur ne va pas passer par le client Munin pour récupérer les données mais par un plugin installé directement sur le serveur.
Dans le schéma suivant, honteusement copier/coller du site officiel, le serveur Munin (Dumbledore) va utiliser le le munin-node local pour aller chercher, via SNMP, les informations sur la machine hôte (Netopia).

Comment ajouter un hôte SNMP à superviser ?
Avant tout il faut avoir installé le serveur Munin sur une machine GNU/Linux (vous pouvez suivre cet article pour vous aider).
Ensuite, depuis votre serveur, il suffit de saisir la commande suivante pour ajouter l’hôte « netopia ». Il faut bien sûr remplace netopia par le nom (FQND) ou l’adresse IP de votre hôte.
dumbledore:~# munin-node-configure --shell --snmp netopia ln -s /usr/share/munin/plugins/snmp__if_ /etc/munin/plugins/snmp_netopia_if_1 ln -s /usr/share/munin/plugins/snmp__if_err_ /etc/munin/plugins/snmp_netopia_if_err_1 ...
Comme vous pouvez le voir, la commande munin-node-configuration avec le tag –snmp va scanner la MIB SNMP de votre machine hôte et proposer une configuration automatique de tout les plugins (graphes) reconnus dans le répertoire /usr/share/munin/plugins. Vous pouvez ensuite les activer dans votre configuration de Munin en faisant un copier/coller de toutes les lignes ln -s … ou bien plus simplement en remplaçant la commande précédente par:
dumbledore:~# munin-node-configure --shell --snmp netopia | sh
Par défaut, munin-node-configuration utilise public comme communauté SNMP, il est possible de la configurer en ajoutant:
--snmpcommunity public
La version de SNMP à utiliser peut également être configurée:
--snmpversion 3
Il faut ensuite ajouter les lignes suivantes à votre fichier de configuration du serveur Munin (en laissant bien l’adresse IP 127.0.0.1 !!!):
[netopia]
address 127.0.0.1
use_node_name no
Appliquer la nouvelle configuration à votre serveur Munin
Une fois vos différents hôtes ajoutés selon la procédure précédente, vous devez faire prendre en compte la nouvelle configuration avec la commande:
service munin-node restart
Les nouveaux graphes devraient apparaître après quelques minutes:

Dans certains cas, si les graphes n’arrivent pas, il peut être utile de relancer complètement le serveur Munin en saisissant:
su - munin --shell=/bin/sh /usr/share/munin/munin-update
Conclusion
Avez vous des avis sur Munin, l’utiliser vous avec un pooling SNMP ?
Des scripts et astuces à partager ?
Source: Site officiel de Munin.








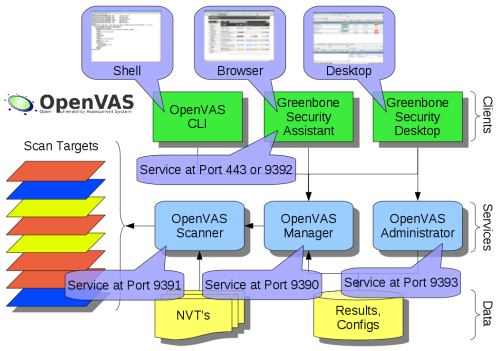
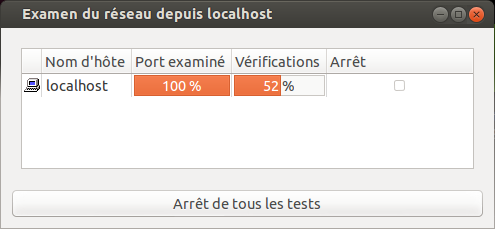
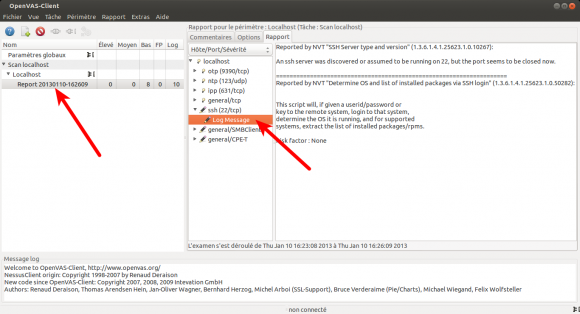
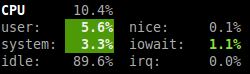








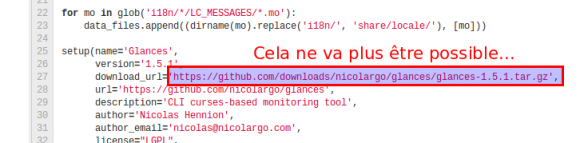
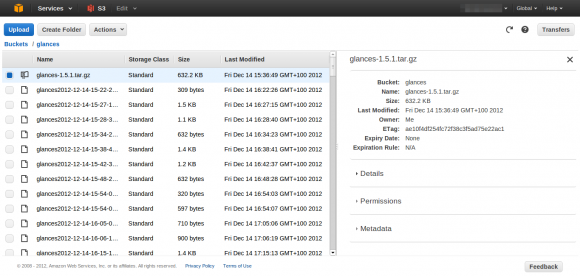
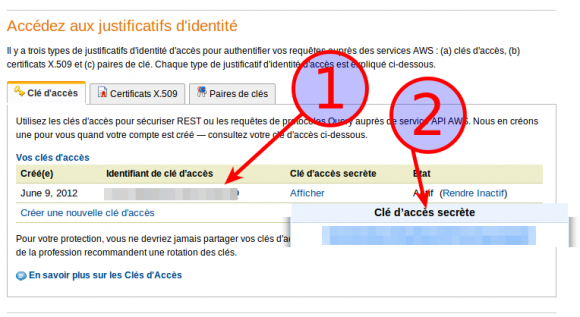


 Je viens de mettre à jour mon dépôt GitHub des scripts de post installation d’Ubuntu pour prendre en compte le version 12.10 (Quantal). Pour rappel, ces scripts sont un moyen simple et modulaire de faire automatiquement un ensemble d’actions après l’installation standard du système d’exploitation.
Je viens de mettre à jour mon dépôt GitHub des scripts de post installation d’Ubuntu pour prendre en compte le version 12.10 (Quantal). Pour rappel, ces scripts sont un moyen simple et modulaire de faire automatiquement un ensemble d’actions après l’installation standard du système d’exploitation.

 Je viens de lire le mail d’un lecteur concernant ses interrogations sur le choix des logiciels permettant de surveiller son réseau. Comme c’est une question récurrente dans ma boîte mail et que je pense que ses questions et nos réponses peuvent intéresser d’autres personnes, j’ai décidé de lui répondre directement sur le blog.
Je viens de lire le mail d’un lecteur concernant ses interrogations sur le choix des logiciels permettant de surveiller son réseau. Comme c’est une question récurrente dans ma boîte mail et que je pense que ses questions et nos réponses peuvent intéresser d’autres personnes, j’ai décidé de lui répondre directement sur le blog.
 Bien que je pense qu’il vaille mieux utiliser un logiciel en Anglais plutôt qu’un logiciel (mal traduit) en Français, la problématique de l’internationalisation des développements viendra tôt ou tard sur le tapis si vous avez des utilisateurs de plusieurs pays.
Bien que je pense qu’il vaille mieux utiliser un logiciel en Anglais plutôt qu’un logiciel (mal traduit) en Français, la problématique de l’internationalisation des développements viendra tôt ou tard sur le tapis si vous avez des utilisateurs de plusieurs pays.