La rédaction des billets de ce blog nécessite de travailler sur plusieurs systèmes d’exploitations différents. Plutôt que de monter une salle machine dans ma maison (pas sur que ma compagne soit d’accord), j’ai donc opté pour un virtualisation sur un serveur dédié OVH qui a le gros avantage de disposer d’une RAM conséquente de 16 Go (pour une machine en l’an 2012). Travaillant la plupart du temps du temps sous Linux, mon choix c’est donc porté sur la solution Qemu/KVM (Kernel-based Virtual Machine).
Installation de Qemu/KVM
Pour que Qemu/KVM ait des performances acceptables, il faut vérifier que votre processeur soit compatible avec les extensions de virtualisation. Sous Linux, il est facile de vérifier cela avec la ligne de commande suivante.
[cce lang= »bash »]
egrep ‘^flags.*(vmx|svm)’ /proc/cpuinfo >/dev/null && echo OK || echo KO
[/cce]
Sur mon serveur de test (Kimsufi 16G chez OVH) pas de problème de ce coté là. J’obtiens un beau OK.
Le serveur peut donc supporter la virtualisation hardware. Chez OVH, le noyau par défaut est statique, il n’est donc pas possible d’ajouter dynamiquement des modules (comme le kvm_intel par exemple). Il faut donc suivre cette procédure. La dernière version des noyaux semble intégrer par défaut les modules KVM.
On peut ensuite passer à l’installation des briques logicielles (environ 257 Mo à télécharger):
- qemu-kvm – Full virtualization on x86 hardware
- virtinst – Programs to create and clone virtual machines
- libvirt-bin – the programs for the libvirt library
On utilise les versions disponibles dans les dépôts Debian:
[cc lang= »bash »]
sudo apt-get install qemu-kvm virtinst libvirt-bin
[/cc]
Un petit reboot de la machine pour être sûr que tous les modules sont chargés avant de poursuivre.
Création de sa première machine virtuelle (VM)
Nous allons commencer par créer une machine virtuelle avec comme système hôte une Ubuntu Desktop 11.10. Une machine virtuelle a besoin d’un conteneur dans lequel elle va pourvoir s’exécuter: ce conteneur s’appelle une image disque. Ensuite, il faudra installer le système hôte à l’intérieur de cette image disque.
Il est possible d’utiliser la ligne de commande pour effectuer ces opérations (ce qui ouvre la voie à une automatisation par scripts). Nous aborderons cela un peu plus loin dans l’article. Pour commencer, nous allons utiliser le module libvirt-manager qui propose une interface graphique (GTK) permettant d’administrer à distance (via un tunnel SSH) son serveur d’hypervision Qemu/KVM.
On commence par vérifier que le daemon d’administration est bien lancé sur le serveur d’hypervision (ce qui devrait être le cas si vous avez suivi les étapes d’installations de ce billet):
[cc lang= »bash »]
sudo /etc/init.d/libvirt-bin status
Checking status of libvirt management daemon: libvirtd running.
[/cc]
Ensuite il faut ajouter votre utilisateur (nicolargo dans mon cas) dans les groupes ‘libvirt‘ et ‘kvm‘:
[cc lang= »bash »]
sudo usermod -a -G libvirt nicolargo
sudo usermod -a -G kvm nicolargo
[/cc]
Sur la machine GNU/Linux cliente (disposant d’une interface graphique), il faut installer les packages (par exemple sous Debian/Ubuntu):
[cc lang= »bash »]
sudo apt-get install virt-manager
[/cc]
Au lancement du client, il faut cliquer sur le menu File > Add connection…
Puis paramétrer la connexion vers votre serveur:
 Notre serveur est alors disponible dans la liste, on peut alors configurer ses propriétés:
Notre serveur est alors disponible dans la liste, on peut alors configurer ses propriétés:

On configure le type de réseau que l’on va utiliser. Comme je ne dispose que d’une seule adresse publique sur mon serveur OVH Kimsufi, j’utilise la translation d’adresse (voir l’explication dans un chapitre suivant) qui est configurée par défaut:

Puis on configure les répertoires ou l’on pourra trouver les ISOs pour l’installation des machines hôtes:



Et voila le résultat après téléchargement de quelques images ISO depuis le répertoire ~/iso (le serveur disposant d’une accès 100 Mbs direct sur Internet, cela va assez vite !).

On peut passer à la création de la VM proprement dite en cliquant sur le bouton « Create a new virtual machine ». On accède alors à un wizard:
On entre le nom de la VM (sans espace):

Puis l’image ISO qui va nous servir pour l’installation du système d’exploitation (le « Browse » sur le serveur peut prendre un certain temps):

On défini ensuite les ressources de la VM (CPU et mémoire). A noter que la limite à 2 Go de RAM sur ma configuration de test:

On donne ensuite la taille de l’image disque qui contiendra notre VM. Je conseille 16 Go pour les OS récents.

Enfin on finalise la configuration coté réseau (NAT) et hyperviseur (KVM):

Une fenêtre avec un déport d’affichage devrait alors s’afficher et l’installation du système guest (Ubuntu 11.10) commencer:
 Il ne vous reste plus qu’à finaliser l’installation !
Il ne vous reste plus qu’à finaliser l’installation !
Utilisation de sa VM
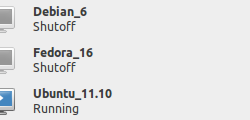
Une fois l’installation de la VM effectuée (voir le chapitre précédant). Celle-ci devrait apparaître dans la liste proposé par Virtual Machine Manager. Pour la lancer, il faut sélectionner la VM puis cliquer sur le bouton ‘play’ (Power On the virtual machine):

Et voilà le travail:

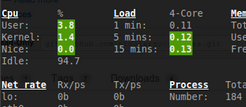
Niveau performance ?
Il ne faut pas s’attendre à des miracles. La virtualisation par Qem/KVM bien qu’aillant fait de gros progrès dans les dernières versions restent en dessous d’une solution comme VmWare ou Xen. Elles sont par contre suffisante dans mon cas ou je souhaite valider des procédures et des logiciels système et réseau.
Gestion en ligne de commande
Création de l’image disque
On commence par créer un répertoire ~/vm qui va contenir toutes mes images disques:
[cc lang= »bash »]
mkdir ~/vm
[/cc]
Puis on utilise la commande qemu-img pour générer l’image disque « vierge »:
[cc lang= »bash »]
cd ~/vm
qemu-img create -f qcow2 debian6server.qcow2 16G
[/cc]
Cette dernière commande va donc générer une image disque nommée debian6server.qcow2 de type qcow2 (voir ci-dessous la liste des types disponibles sous Debian 6) avec une taille maximale de 16 Giga octets.
Sur mon système, la liste des « types » d’image disque est la suivante:
- raw: pas de compression, l’image disque est directement « dumpée » dans un fichier
- host_device
- qcow2: format par défaut de Qemu (Qemu Image Format)
- qcow: ancien format utilisé par Qemu (ne pas utiliser pour la création de nouvelle image disque)
- vdi: format compatible avec VirtualBox
- vmdk: format compatible avec VMWare
- vpc: format compatible avec VirtualPC
Il est possible de convertir une image d’un format à un autre. Par exemple, si vous avez une image au format VMWare et que vous voulez la convertir vers un format Qcow2, il suffit de saisir la commande suivante:
[cc lang= »bash »]
qemu-img convert -f vmdk disk.vmdk -O qcow2 disk.qcow2
[/cc]
Création de la VM
Pour installer la VM, nous avons besoin de l’image ISO du système d’exploitation à installer (Debian 6 server dans mon exemple). On va donc télécharger cette image sur notre serveur (c’est dans ces moments là que l’on est heureux d’avoir un serveur avec une connexion à 100Mbps vers Internet…):
[cc lang= »bash »]
mkdir ~/iso
cd ~/iso
wget http://cdimage.debian.org/debian-cd/6.0.3/i386/iso-cd/debian-6.0.3-i386-CD-1.iso
[/cc]
Maintenant que nous disposons de l’image disque ~/vm/debian6server.qcow2 et du média d’installation ~/iso/debian-6.0.3-i386-CD-1.iso, nous allons créer la machine virtuelle en utilisant la couche d’abstraction libvirt.
Pourquoi utiliser libvirt plutôt que d’utiliser directement les commandes équivalentes Qemu ? Si demain vous décidez de changer votre système de virtualisation, vos procédures/scripts resteront les mêmes. En effet libvirt communique de manière transparente vers un grand nombre de systèmes de virtualisation en proposant en bonus une API de développement (notamment en Python).
On utilise donc la commande suivante pour créer la VM:
[cc lang= »bash »]
virt-install –ram=2047 –name=debian6server –file=/home/nicolargo/vm/debian6server.qcow2 –cdrom=/home/nicolargo/iso/debian-6.0.3-i386-CD-1.iso –hvm –vnc –noautoconsole
[/cc]
Note: la commande virt_install ne semble pas trop aimer les ~ dans les paths. Il faut donc donner le chemin absolu.
Note2: La taille maximale de RAM que je peux allouer est de 2047Mo.
Cette commande va donc créer une VM nommée debian6server qui disposera de 2 Go de RAM (d’ou l’avantage de faire tourner votre hyperviseur sur une machine disposant de pas mal de RAM / 16 Go dans mon cas sur une Kimsufi 16G).
Si tout est ok, le message suivant devrait s’afficher:
Domain installation still in progress.
You can reconnect to the console to complete the installation process.
Pour l’accès à la console (déport VNC via un tunnel SSH), je vous conseille d’utiliser l’interface d’administration de libvirt que vous pouvez lancer sur un PC client disposant d’une interface graphique.
Gestion du réseau par translation
Mon serveur dispose d’une seule adresse IP publique. Les VM auront donc des adresses IP privées et l’on utilisera la translation s’adresse (NAT) pour permettre au VM de sortir sur Internet (voir ce billet pour la création d’un réseau par NAT).
Certaines configurations sont à faire sur votre serveur:
[cc]
sudo sh -c « echo 1 > /proc/sys/net/ipv4/ip_forward »
[/cc]
[cc]
sudo vi /etc/sysctl.conf
# Uncomment the next line to enable packet forwarding for IPv4
net.ipv4.ip_forward=1
[/cc]
Si vous utilisez des règles Iptables alors il faut ajouter les lignes suivantes dans votre scripts (attention de bien vérifier que votre script ne repositionne pas la valeur net.ipv4.ip_forward à 0… je me suis fais avoir):
[cc]
# Qemu rules (NAT VM and allow VM to DHCP)
/sbin/iptables -t nat -A POSTROUTING -s 192.168.122.0/24 ! -d 192.168.122.0/24 -j MASQUERADE
/sbin/iptables -A INPUT -i virbr0 -j ACCEPT
/sbin/iptables -A OUTPUT -o virbr0 -j ACCEPT
/sbin/iptables -A INPUT -i virbr0 -p udp -m udp –dport 53 -j ACCEPT
/sbin/iptables -A INPUT -i virbr0 -p tcp -m tcp –dport 53 -j ACCEPT
/sbin/iptables -A INPUT -i virbr0 -p udp –dport 67:68 –sport 67:68 -j ACCEPT
/sbin/iptables -A FORWARD -d 192.168.122.0/24 -o virbr0 -m state –state RELATED,ESTABLISHED -j ACCEPT
/sbin/iptables -A FORWARD -s 192.168.122.0/24 -i virbr0 -j ACCEPT
/sbin/iptables -A FORWARD -i virbr0 -o virbr0 -j ACCEPT
echo 1 > /proc/sys/net/ipv4/ip_forward
[/cc]

Petite note pour les guests « BSD »
Pour un guest sous OpenBSD, il faut penser à effectuer les actions suivantes pour faire fonctionner correctement la carte réseau:
- arrêter la VM
- éditer le fichier /etc/libvirt/qemu/OpenBSD_5.0.xml
[cce]
<interface type=’network’>
…
<model type=’e1000′>
</interface>
[/cce]
Sources utilisées lors de la rédaction de cet article:





 Dans quelques semaines, la version 12.04 (alias Precise Pangolin) de la distribution Ubuntu va sortir. C’est une version LTS (« Long Time Support ») qui sera intéressante pour une utilisation aussi bien personnelle que professionnelle. L’orientation grand-public de Canonical (l’éditeur d’Ubuntu) est, je le pense, un bien pour la promotion et la diffusion des systèmes GNU/Linux.
Dans quelques semaines, la version 12.04 (alias Precise Pangolin) de la distribution Ubuntu va sortir. C’est une version LTS (« Long Time Support ») qui sera intéressante pour une utilisation aussi bien personnelle que professionnelle. L’orientation grand-public de Canonical (l’éditeur d’Ubuntu) est, je le pense, un bien pour la promotion et la diffusion des systèmes GNU/Linux.











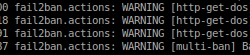
 Par ces temps de dématérialisation des espaces de stockages, les services en ligne comme Dropbox et SpiderOak focalisent à la fois des commentaires admiratifs (facilité d’utilisation, fiabilité) et réticents (protection de la vie privée, pérennité du service à moyen et long terme, prix). Du bon coté de la force, les alternatives libres et auto-hébergées commencent à pointer le bout de leurs nez. Une de ces solutions a eut droit à son petit buzz ces dernières semaines:
Par ces temps de dématérialisation des espaces de stockages, les services en ligne comme Dropbox et SpiderOak focalisent à la fois des commentaires admiratifs (facilité d’utilisation, fiabilité) et réticents (protection de la vie privée, pérennité du service à moyen et long terme, prix). Du bon coté de la force, les alternatives libres et auto-hébergées commencent à pointer le bout de leurs nez. Une de ces solutions a eut droit à son petit buzz ces dernières semaines: 




