7/10/2013 Update: billet mis à jour pour la version 3.0 de Bootstrap
Avec la généralisation des technologies JS, CSS3 et HTML5, il est aujourd’hui possible de faire des sites Web qui n’ont rien à envier aux interfaces des logiciels que l’on peut trouver sur nos machines. Le revers de la médaille est une complexité croissante qui nécessite de faire appel à des professionnels . Quand vous devez faire un site personnel ou pour une association, il est difficile, à moins de s’appeler Cresus, de passer par un Web designer.
Heureusement des frameworks libres permettent avec un minimum d’investissement et de connaissances de bâtir des sites Web dans les règles de l’art. Nous allons dans ce billet parler du plus médiatique d’entre eux: Bootstrap. L’idée n’est pas de traduire la documentation officielle qui est par ailleurs très bien faite, mais de partager avec-vous mes méthodes que je suis en train d’utiliser pour développer le prochain thème du Blog de Nicolargo qui sera, vous l’avez compris largement basé sur Bootstrap.

 Créer l’arborescence de son projet
Créer l’arborescence de son projet
Nous allons commencer par créer l’arborescence générale de notre site qui sera stocké, pour illustrer ce billet, dans le répertoire ~/projet de notre disque dur. On y télécharge&&décompresse la dernière version stable de Bootstrap.
mkdir ~/projet
cd ~/projet
wget https://github.com/twbs/bootstrap/releases/download/v3.0.0/bootstrap-3.0.0-dist.zip
unzip bootstrap-3.0.0-dist.zip
rm bootstrap-3.0.0-dist.zip
rm -rf bootstrap
mv dist bootstrap
Note: Contrairement à la plupart des tutos que l’on peut trouver sur le net, je préfère conserver le répertoire bootstrap intact et utiliser d’autres répertoires pour stocker mes configurations spécifiques. Ainsi, la mise à jour de Bootstrap n’aura aucun impact sur mon site.
En plus de Bootstrap, j’ajoute également la dernière version du projet Font Awesome qui met à notre disposition un nombre important et varié d’icônes jusqu’à une résolution de 280 pixels.

cd ~/projet
git clone git://github.com/FortAwesome/Font-Awesome.git
Les données spécifiques à notre site seront stockées dans l’arborescence suivante (à adapter à vos besoins)
cd ~/projet
mkdir css img js
touch index.html css/style.css
On peut ensuite commencer à éditer la premier page de son site en utilisant son éditeur de texte de prédilection (par exemple avec Geany):
geany index.html
Voici le template que j’utilise:
<!DOCTYPE html>
<html>
<head>
<title>Bootstrap arena</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<!-- Bootstrap -->
<link href="bootstrap/css/bootstrap.min.css" rel="stylesheet" media="screen">
<!-- Font-Awesome -->
<link href="Font-Awesome/css/font-awesome.min.css" rel="stylesheet">
<!-- My style -->
<link href="css/style.css" rel="stylesheet" media="screen">
</head>
<body>
<h1>Hello Bootstrap !</h1>
</body>
<footer>
<script src="http://code.jquery.com/jquery.js"></script>
<script src="bootstrap/js/bootstrap.min.js"></script>
</footer>
</html>
Jusque là rien d’exceptionnel… Vous devriez voir s’afficher « Hello Bootstrap » en chargeant votre page dans un navigateur HTML. C’est à partir de maintenant que l’on va profiter de la puissance de Bootstrap !
Définir vos grilles
Par défaut, Bootstrap utilise un système avec une grille de 12 colonnes (voir le site 960.gs pour une explication de cette dernière phrase). Votre fenêtre de navigateur est ainsi divisée en 12 sections de tailles équivalentes. Vous pouvez l’adapter à votre besoin en gardant ce chiffre à l’esprit. Par exemple pour créer une page Web avec 2 colonnes, il suffit d’ajouter les lignes suivantes entre les balises <body> … </body> de votre fichier HTML.
<div class="container">
<div class="row">
<div class="col-md-8">Article</div>
<div class="col-md-4">Sidebar</div>
</div>
</div>
Ce qui donne une première colonne de taille 8/12 de la taille de votre fenêtre et une autre de 4/12:

On utilise ici une disposition fluide (classe row) qui permet d’adapter dynamique la largeur de vos deux colonnes en fonctions de la taille de votre écran.
Bootstrap génère par défaut des espaces entre deux colonnes (environ 20 pixels pour une dic container). Il est possible de générer des espaces supplémentaire avant ou entre vos colonnes en utilisant le paramètre de classe offset. Par exemple pour créer un espace de taille 1/12 d’écran entre vos deux colonnes, il suffit de modifier votre code de la manière suivante:
<div class="container">
<div class="row">
<div class="col-md-8">Article</div>
<div class="col-md-offset-1 col-md-3">Sidebar</div>
</div>
</div>
On obtient:

Noter bien que la somme des col-md-8 + col-md-offset-1 + col-md-3 est toujours égale à 12. Pour être tout à fait précis, la somme doit être égale à la taille de votre grille dans lequel votre balise row est imbriquée. Comme nous l’avons vu la grille par défaut à une valeur de 12. Mais il est possible d’utiliser une autre valeur en définissant une div chapeau. Par exemple pour définir une grille de 6 et y créer deux colonnes de 4 et de 2, on doit utiliser le code suivant:
<div class="row">
<div class="col-md-6">
<div class="col-md-4">Article</div>
<div class="col-md-2">Sidebar</div>
</div>
</div>
On obtient alors:

« Responsive design » en une ligne
Comme vous pouvez le voir il est possible d’imbriquer des grilles dans d’autres et ainsi découper facilement sa page sans se soucier des redimensionnements de fenêtres. En effet, tout le « responsive design » est géré par Bootstrap. Votre site sera donc automatiquement compatible avec les tablettes et les smartphones !
Le tableau suivant donne la liste des tags que l’on peut utiliser pour rendre son site compatible avec les différents supports:
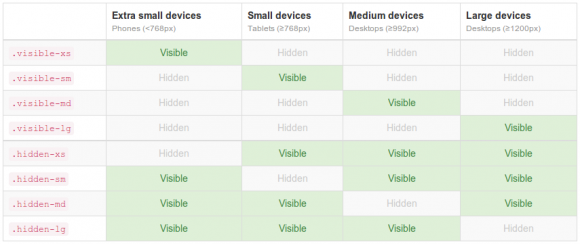
Comment lire ce tableau ? C’est relativement simple. Prenons un exemple. Nous voulons dans notre premier exemple avec deux colonnes (article et sidebar) cacher automatiquement la sidebar quand notre site est consulté depuis un smartphone. Nous allons pour cela afficher les classes .hidden-sm et .hidden-xs de la manière suivante:
<div class="container">
<div class="row">
<div class="col-md-8">Article</div>
<div class="col-md-4 hidden-sm hidden-xs">Sidebar</div>
</div>
</div>
Affichage sur un PC ou une tablette (ou un écran > à 767 pixels):

Affichage sur un smartphone (ou un écran de largeur <= à 767 pixels):

Magique non ?
Passons aux contenus de vos pages
Nous avons maintenant une belle grille « responsive » qu’il va falloir remplir.
En plus des éléments de bases (texte, images, icônes, formulaire), Bootstrap propose des composants avancées (barre de navigation, menu, aperçu d’image, pagination, barre de progression) mais également un système de plugins avec des composants dynamiques en JavaScript (carrousel, popup, menu en accordéon, formulaire dynamique…). Je vous invite à consulter les liens données dans ce chapitre. Des idées pour votre prochain site viendront d’elles même.
Sources utilisées pour rédiger ce billet:
























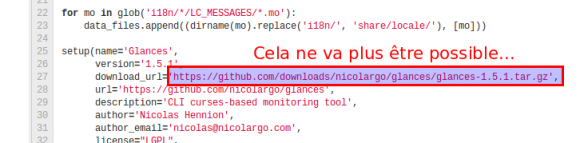
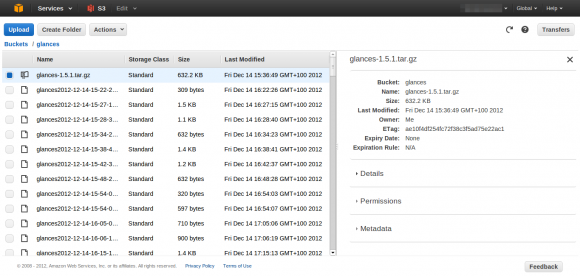
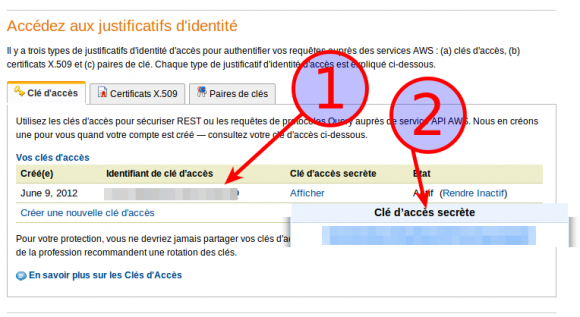


 Je viens de mettre à jour mon dépôt GitHub des scripts de post installation d’Ubuntu pour prendre en compte le version 12.10 (Quantal). Pour rappel, ces scripts sont un moyen simple et modulaire de faire automatiquement un ensemble d’actions après l’installation standard du système d’exploitation.
Je viens de mettre à jour mon dépôt GitHub des scripts de post installation d’Ubuntu pour prendre en compte le version 12.10 (Quantal). Pour rappel, ces scripts sont un moyen simple et modulaire de faire automatiquement un ensemble d’actions après l’installation standard du système d’exploitation.
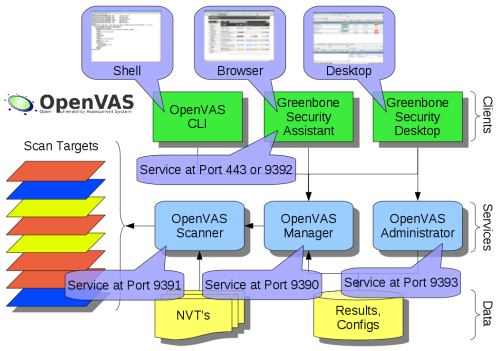
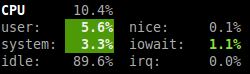
 Je viens de lire le mail d’un lecteur concernant ses interrogations sur le choix des logiciels permettant de surveiller son réseau. Comme c’est une question récurrente dans ma boîte mail et que je pense que ses questions et nos réponses peuvent intéresser d’autres personnes, j’ai décidé de lui répondre directement sur le blog.
Je viens de lire le mail d’un lecteur concernant ses interrogations sur le choix des logiciels permettant de surveiller son réseau. Comme c’est une question récurrente dans ma boîte mail et que je pense que ses questions et nos réponses peuvent intéresser d’autres personnes, j’ai décidé de lui répondre directement sur le blog.