Les serveurs hébergeant des services « Web » deviennent de plus en plus critique: un problème technique sur un site marchand fait baisser le chiffre d’affaire, un autre sur un site d’information peut faire passer le lecteur à la concurrence un dernier sur un blog personnel/professionnel peut impacter directement la crédibilité de l’auteur.
Il est donc important de surveiller ces serveurs comme le lait sur le feu. Les outils de supervision permettent de s’acquitter de cette tache de manière plus ou moins automatique en recevant les alertes par mail, Twitter, SMS…
Nous allons dans ce billet configurer un serveur Shinken (étant un fork de Nagios, le billet est également valable pour la configuration d’un serveur sous Nagios) pour surveiller un blog WordPress tournant sur le pile HTTP Varnish+Nginx.
Avant de commencer
Nous partons sur l’hypothèse ou vous disposer d’un serveur sous Debian avec la pile Varnish+Nginx+Wordpress et un serveur Shinken correctement installé et fonctionnel. Idéalement, la brique Shinken sera installé sur un autre serveur lui même hébergé chez un autre hébergeur. Dans ce cas il faudra mettre en place la couche NRPE entre les deux pour que Shinken puisse correctement collecter les informations sur le serveur Web.
Pour simplifier la configuration et que vous puissiez facilement la tester sur vos blogs/sites personnels, j’ai choisi de réunir les deux briques (Web + Supervision) sur une même machine.
Quoi surveiller ?
C’est la question que j’ai posé sur Twitter il y a quelques jours et j’ai reçu un grand nombre de réponses allant toutes dans le même sens. Faute de temps, je n’ai pas pu exploiter toutes les pistes mais je garde cela sous le coude et je ferai sûrement évoluer ce billet dans le futur.
J’ai donc découpé la supervision en deux groupes de services: système / web.
Pour les services système:
- La charge du serveur: cela permet de s’assurer qu’un processus n’occupe pas toute la CPU et que mon serveur Web (pas très consommateur grâce à l’utilisation de Varnish) aura les ressources pour répondre correctement.
- La mémoire disponible: c’est un des point critique en terme de performance, comme j’utilise des caches en RAM il faut s’assurer que le système dispose toujours d’une marge de manoeuvre au niveau de la mémoire vive disponible.
- La mémoire Swap disponible: quand le système n’a plus de RAM disponible, il utilise la mémoire Swap (disque). Je contrôle donc que cet espace n’est jamais trop occupé.
- RAID1: Mon serveur Dedibox dispose de deux disques durs fonctionnant en RAID1. Je contrôle que les deux disques sont fonctionnels avec un plugin maison.
- Espace libre sur la partition système: j’ai installé mon serveur Web sur un distribution Debian Squeeze avec le partitionnement par défaut qui affecte une seule partition à /. Je surveille donc que l’espace disque disponible ne devienne pas trop bas.
- Espace libre sur la partition de backup: mon serveur est hébergé chez Online.net qui propose un espace de stockage accessible en FTP ou j’archive avec RSnapShot tous les répertoire critiques de mon serveur. J’ai donc monté cet espace FTP sur un répertoire de mon disque et j’en surveille l’espace disponible.
- Nombres de processus actifs: Un trop grand nombre de processus tournant sur le serveur peut mettre en évidence un bug sur un des processus. Je contrôle que ce nombre ne soit pas trop important.
- Nombres d’utilisateurs connectés simultanément: Comme je suis le seul admin de ce serveur, j’ai mis une alerte qui me prévient quand deux utilisateurs sont connectés simultanément.
Pour les services Web:
- On commence par surveiller que les processus critiques sont lancés: Varnish (2 processus varnishd), NGinx (5 nginx) et SSH (1 sshd). On passage on vérifie que le nombre de processus est conforme à notre configuration.
- On surveille les ports en écoutes (local): TCP/80 (Varnish), TCP/8080 (NGinx), TCP/22 (SSH)
- Pour le site Web à surveiller (par exemple www.mondomaine.com), on contrôle que les URLS suivantes sont bien accessibles:
- http://www.mondomaine.com (home page)
- http://www.mondomaine.com/sitemap.xml.gz (le sitemap utilise pour votre référencement)
- http://www.mondomaine.com/googleXXXXXXXXX.html (le fichier fourni par Google pour faire le check vers ces services)
- Attaques DOS/DDOS: un plugin me permet de détecter si mon site est victime d’une attaque DOS (facile à bloquer) ou DDOS (bon courage… hein Korben :))
Cette liste est bien sûr très restrictive, j’attend vos idées dans les commentaires !
Les confs, les confs !
L’idée est de fournir les configurations « brutes de décoffrages ». Si vous avez des problèmes pour appliquer cette configuration sur votre serveur, je vous conseille de consulter les billet de la page sur la supervision de ce blog.
La configuration des services système:
[cce]
# Define a service to check the disk space of the root partition
# on the local machine. Warning if < 20% free, critical if
# < 10% free space on partition.
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Root Partition
check_command check_local_disk!10%!5%!/
}
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Backup Partition
check_command check_local_disk!10%!5%!/mnt/backup
}
# Define a service to check the number of currently logged in
# users on the local machine.
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Current Users
check_command check_local_users!2!3
}
# Define a service to check the number of currently running procs
# on the local machine. Warning if > 250 processes, critical if
# > 400 processes.
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Total Processes
check_command check_local_procs!250!400!RSZDT
}
# Check memoire avec script check_memory
# https://blog.nicolargo.com/2008/07/surveiller-la-memoire-de-vos-serveurs-avec-nagios.html
# -w 5% -c 1%
define service{
use local-service
host_name localhost
service_description Memory
check_command check_mem!10%!5%
}
# Define a service to check the load on the local machine.
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Current Load
check_command check_local_load!5.0,4.0,3.0!10.0,6.0,4.0
}
# Define a service to check the swap usage the local machine.
# Critical if less than 10% of swap is free, warning if less than 20% is free
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Swap Usage
check_command check_local_swap!20!10
}
# Check RAID (hardware)
define service{
use local-service ; Name of service template to use
host_name localhost
service_description RAID1
check_command check_raid
}
[/cce]
puis les services Web:
[cce]
# Define a service to check SSH on the local machine.
define service{
use local-service ; Name of service template to use
host_name localhost
service_description SSH
check_command check_ssh
#notifications_enabled 0
}
# Varnish process
# /usr/lib/nagios/plugins/check_procs -w 2:2 -c 1:1024 -C varnishd
define service{
use local-service
host_name localhost
service_description Varnish process
check_command check_local_process!2:2!1:1024!varnishd
}
# Check process
# /usr/lib/nagios/plugins/check_procs -w 5:5 -c 1:1024 -C nginx
define service{
use local-service
host_name localhost
service_description Nginx process
check_command check_local_process!5:5!1:1024!nginx
}
# Define a service to check Varnish
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Varnish access
check_command check_url!http://localhost/
}
# Define a service to check HTTP on the local machine.
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Nginx access
check_command check_url!http://localhost:8080/
}
# Define a service to check HTTP on the local machine.
define service{
use local-service ; Name of service template to use
host_name localhost
service_description URL Blog check
check_command check_url!http://www.mondomaine.com/
}
# Define a service to check URL
# http://www.mondomaine.com/googleXXXXXXXX.html
define service{
use local-service
host_name localhost
service_description URL Google check file
check_command check_url!http://www.mondomaine.com/googleXXXXXXXXXX.html
service_dependencies localhost,HTTP Blog
}
# Define a service to check URL
# https://blog.nicolargo.com/sitemap.xml.gz
define service{
use local-service
host_name localhost
service_description URL Sitemap
check_command check_url!http://www.mondomaine.com/sitemap.xml.gz
service_dependencies localhost,HTTP Blog
}
# Define a DDOS detection service
# https://blog.nicolargo.com/?p=4100
# Warning: >50 SYN_RECV
# Critical: >70 SYN_RECV
define service{
use local-service
host_name localhost
service_description DDOS detect
check_command check_ddos!50!70
}
[/cce]
Et voilà ce que cela donne dans mon Shinken/Thruk:








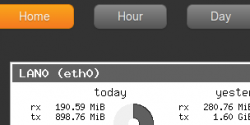





 Détail du code
Détail du code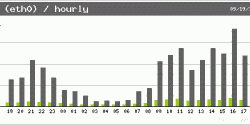








{kind=link}