Le discours de Steve Jobs à Stanford en VOSTFR
Les principales caractéristiques
- Fond d’écran: Disponible ici
- GTK: Look des fenêtre Equinox Evolution Dawn + icônes Faenza darkest
- Conky: Thème Orange
Le discours de Steve Jobs à Stanford en VOSTFR
Petit pense-bête à usage intern(et): gérer les utilisateurs dans ses groupes sous GNU/Linux et en ligne de commande.
Pour changer le groupe primaire de l’utilisateur nicolargo à admin, il suffit d’utiliser la commande usermod:
usermod -g admin nicolargo
Pour ajouter un groupe secondaire networkadmin un utilisateur existant nicolargo, c’est encore la commande usermod qu’il faut utiliser:
usermod -a -G networkadmin nicolargo
Pour ajouter le nouvel utilisateur ritchy et lui configurer un comme groupe primaire admin, il suffit d’utiliser la commande useradd:
useradd -g admin ritchy
Pour ajouter le nouvel utilisateur ritchy et lui configurer un comme groupe secondaire networkadmin, il suffit d’utiliser la commande useradd:
useradd -G networkadmin ritchy
A noter qu’il est possible d’utiliser l’option -G avec plusieurs groupes. Exemples pour ajouter ritchy au groupe secondaire networkadmin et systemadmin:
useradd -G networkadmin,systemadmin ritchy
Rien de plus simple avec la commande groups:
# groups ritchy ritchy: networkadmin systemadmin

Ce billet est le premier d’une série de 5 articles sur Cluster MySQL écrite par Rémy Verger (auteur invité).
Je rappelle que ce billet est le second d’une série de 5 billets:
1. Introduction
2. Concepts de base de MySQL Cluster / Configuration simple-multi serveurs
3. Installation
4. Demarrage du MySQL Cluster
5. Commande d’administration
—
MySQL Cluster est constitué de trois briques:
Nous appelons ces processus de cluster les noeuds du cluster. Mettre en place la configuration du cluster implique la configuration de chaque noeud dans le cluster, et la configuration de chaque moyen de communication entre les noeuds du cluster.
MySQL Cluster est actuellement configuré avec le pré-requis que les noeuds sont homogènes en terme de puissance processeur, espace mémoire et largeur de bande. De plus, pour activer un point de configuration, il a été décidé de placer toute la configuration du cluster dans un seul fichier de configuration.
De plus, il y a un nombre arbitraire de clients connectés au cluster. Ils sont de deux types: ces clients accèdent au serveur de management, et émettent des commandes pour lancer ou arrêter correctement des noeuds, lancer ou arrêter la trace serveur (pour les versions de débogage), pour afficher la configuration courante, voir l’état des noeuds du cluster, afficher les versions et noeuds, lancer les sauvegardes, etc.
Nous allons configurer un cluster de deux noeuds, deux serveurs de management, deux LVS en FailOver, et deux serveurs SQL.

Naturellement, les machines multi-processeurs et celles aux fréquences supérieures seront plus rapides. Les besoins en RAM des processus du Cluster MySQL sont relativement raisonnables.
Les communications entre les noeuds du Cluster MySQL ne sont pas chiffrées ou protégées de quelque manière que ce soit. La seule solution pour protéger les transmissions à l’intérieur du Cluster MySQL est de placer le Cluster MySQL dans un réseau protégé. Si vous envisagez d’utiliser le Cluster MySQL pour une application Web, il est recommandé que le Cluster MySQL soit placé derrière un pare-feu, et non pas dans la zone démilitarisée (DMZ) ou ailleurs.
Configurer un Cluster MySQL sur un réseau privé ou protégé donne au Cluster MySQL l’exclusivité de la bande passante. En utilisant un switch dédié au Cluster MySQL aide à la protection contre les accès non autorisés, et il protège les noeuds des interférences causées par les autres machines sur le réseau. Pour une stabilité accrue, vous pouvez utiliser des switchs redondants et des cartes réseau doubles pour supprimer du réseau les points de panne.
Nous avons choisis de virtualiser l’ensemble des serveurs sur Vmware ESXi, cela nous donne une meilleure souplesse quand au changement matériel ( augmentation de RAM / Rajout de carte réseau ) .
Les clients contactent l’application hébergé sur nos serveurs, sur ces serveurs nous inscrivons les adresses des LoadBalancer . Le protocole de routage Round Robin alternera l’envoie des paquets sur les serveurs SQL définis dans sa pool .
Les serveurs SQL ne contiennent pas les données propres a la base de données, ils ne sont la que pour traiter les requètes . A leurs tours ils contactent les Noeuds qui possèdent la totalité de la base de données chargé dans leur RAM.
Les serveurs de management servent a renseigner les serveurs du cluster. C’est lui qui définit les rôles des serveurs . Et répartir la charge automatiquement entre les Noeuds .
L’ensemble des données stocké en RAM sont répliqué entre tous les nœuds, et la charge et partagé entre le nombre de serveurs nœud .
Ce billet est le premier d’une série de 5 articles sur Cluster MySQL écrite par Rémy Verger (auteur invité).
La problématique de répartition des données est un problème majeur des infrastructures de gestion de l’information. Alors que l’approche historique consiste à dimensionner un seul serveur de façon à ce qu’il absorbe toute la charge, on observe depuis plusieurs années une tendance inverse, inspirée des techniques de RAID pour les volumes de stockage, qui consiste a prendre un très grand nombre de machines a faible coût pour former un cluster de stockage.
Il existe plusieurs façons différente de mettre en place un Clusteur de Stockage avancé, que je vais vous faire découvrir. Cette série de billet va se focaliser sur la solution MySQL Cluster, la base de données distribuée de MySQL.
J’installerais MySQL Cluster sur une distribution CentOS, qui peut également être adapter a une distribution RedHat, comme il s’agit de paquet disponible dans les dépôts ReDHat Cluster Suite.
De plus vous trouverez des machines virtuelles sous VMware avec l’ensemble de l’architecture .
Voici le sommaire des 5 billets:
1. Introduction
2. Concepts de base de MySQL Cluster / Configuration simple-multi serveurs
3. Installation
4. Demarrage du MySQL Cluster
5. Commande d’administration
On commence de ce pas par le premier article !

Dans le domaine des systèmes de gestion de bases de données,MySQL fournit une solution élégante pour réaliser un cluster à faible coût permettant d’atteindre un niveau de disponibilité proche des 99,999% annuel.
Un Cluster MySQL est un groupe de processus qui s’exécutent sur plusieurs serveurs MySQL, des noeuds NDBCluster, et des processus d’administration, ainsi que des processus d’accès spécialisés. Tous ces programmes fonctionnent ensemble pour former un Cluster MySQL. Lorsque les données sont stockées dans le moteur NDBCluster, les tables sont réparties sur les noeuds NDBCluster. Ces tables sont directement accessibles depuis tous les autres serveurs MySQL faisant partie du Cluster. Par conséquent, si une application met à jour une ligne, tous les autres serveurs le verront immédiatement.
Les données stockées dans le moteur de table de MySQL Cluster peuvent être dupliquées, et sont capables de gérer une indisponibilité d’un noeud sans autre impact que l’annulation des transactions qui utilisaient ces données.
Elle permet de répartir des données sur plusieurs serveurs sans avoir de point individuel de défaillance. Contrairement aux moteurs MyISAM et InnoDB généralement utilisés avec MySQL, l’exploitation effective du cluster nécessite l’utilisation du moteur NDB, qui contient plusieurs restrictions, comme l’absence d’index FULLTEXT.
MySQL est capable, depuis la version 4.1 et grâce au moteur de stockage NDB de gérer une grappe de serveurs complète.
Sa structure repose sur la duplication données, c’est-à-dire que chaque nœud fera partie d’un groupe de nœud qui posséderont tous la totalité de la base

Un protocole implémenté dans chaque nœud s’occupe d’adresser chaque transaction aux différents nœuds concernés dans la grappe, il faut un minimum de 3 machines pour établir une solution de clustering MySQL et une machine (qui peut elle-même intégrer un serveur MySQL) qui va jouer le rôle de répartiteur de charge en redirigeant les requêtes sur les nœuds disponibles et les moins occupés.
Par rapport à un système de réplication, la redondance est améliorée : si un nœud tombe en panne, sa charge est automatiquement reprise par les autres nœuds.
L’ajout d’un nouveau nœud peut se faire sans avoir besoin de repartitionner la base, il suffit de le faire reconnaître par la grappe et le redémarrage d’un nœud peut se faire sans avoir à redémarrer la grappe.
Du point de vue de MySQL, chaque nœud fait partie d’un ensemble qui pourrait être reconnue comme une seule machine.
Pour le programmeur, il doit programmer son application pour communiquer avec le répartiteur de charge.
Cette solution s’adapte parfaitement lorsque la disponibilité et la sécurité des données est un problème critique et que l’on recherche un partitionnement technique responsable de l’écriture. Couplé a des fonctionnalités temps réel et a une API de programmation asynchrone NDB Cluster s’adresse principalement aux exigences du marché des télécommunications.
Vous pouvez vous rendre sur la page suivante pour voir la liste exhaustive des fonctions proposées dans la version communautaire (gratuite et open-source) de MySQL Cluster.
Mes derniers billets traitaient de VnStat (le logiciel pour surveiller les débits de vos interfaces Ethernet) et de Node.js (le framework permettant de créer facilement des applications réseaux coté serveur). C’est donc dans ma logique toute cartésienne, que j’ai développé un javascript permettant de disposer d’une interface Web pour consulter ces statistiques de débits sans avoir à installer un serveur Web et son plugin PHP (comme c’est le cas avec le VnStat PHP frontend).
Ce script, disponible sous licence GPL v3, s’appelle VnStat.js est disponible dans mon GitHub à l’adresse suivante:

https://github.com/nicolargo/vnstat.js
Pour fonctionner correctement, VnStat.js nécessite:
On commence par récupérer la dernière version de VnStat.js depuis le dépôt Git:
[cce lag= »bash »]
cd ~
git clone git://github.com/nicolargo/vnstat.js.git
cd vnstat.js
[/cce]
Pour les personnes utilisant NPM (le package manager de Node.js), vous pouvez l’utiliser pour installer VnStat.js. Suivre les instructions de cette page.
Pour lancer le noeud VnStat.js, il suffit de saisir les commandes suivantes:
[cce lag= »bash »]
cd ~/vnstat.js
node ./vnstat.js
[/cce]
Le « node » va se mettre en écoute sur le port TCP 1337 de votre serveur (il faut donc ajouter une règle pour autoriser les requêtes entrantes vers ce port si vous avez un firewall).
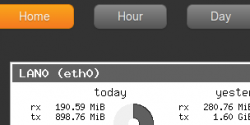
A l’ouverture de l’URL http://adressedevotremachine:1337/ dans un navigateur compatible HTML5, la page principale suivante va s’afficher:

Elle affiche le résumé des statistiques de VnStat ainsi que le top 10 des journées. Le menu du haut permet de naviguer vers des statistiques plus ciblés.
Par heures (avec à la fois la vue graphique et textuelle):

Et ainsi de suite pour les jours, semaines (à noter qu’il n’y a pas de graphe spécifique par semaine généré par vnstati) et enfin par mois.
Le design de VnStat.js peut bien entendu être adapté à vos besoins en éditant le fichier css/style.css (CSS3). Si vous avez besoin de changer le port TCP d’écoute du node, il y a une variable pour cela dans le fichier lib/server.js.
C’est mon premier développement avec le framework Node.js, il y a sûrement des améliorations à faire mais la structure reste assez didacticiel pour servir de base pour d’autre développement du même type.
Comme vous avez pu le remarquer, le node VnStat.js est lancé à la main dans ce billet. Si vous souhaitez mettre en production ce script et le lancer automatiquement au démarrage de votre machine, je vous conseille la lecture du billet de Vincent sur son blog qui regorge d’information sur ce superbe framework qu’est Node.js.

Les serveurs hébergeant des services « Web » deviennent de plus en plus critique: un problème technique sur un site marchand fait baisser le chiffre d’affaire, un autre sur un site d’information peut faire passer le lecteur à la concurrence un dernier sur un blog personnel/professionnel peut impacter directement la crédibilité de l’auteur.
Il est donc important de surveiller ces serveurs comme le lait sur le feu. Les outils de supervision permettent de s’acquitter de cette tache de manière plus ou moins automatique en recevant les alertes par mail, Twitter, SMS…
Nous allons dans ce billet configurer un serveur Shinken (étant un fork de Nagios, le billet est également valable pour la configuration d’un serveur sous Nagios) pour surveiller un blog WordPress tournant sur le pile HTTP Varnish+Nginx.
Nous partons sur l’hypothèse ou vous disposer d’un serveur sous Debian avec la pile Varnish+Nginx+Wordpress et un serveur Shinken correctement installé et fonctionnel. Idéalement, la brique Shinken sera installé sur un autre serveur lui même hébergé chez un autre hébergeur. Dans ce cas il faudra mettre en place la couche NRPE entre les deux pour que Shinken puisse correctement collecter les informations sur le serveur Web.
Pour simplifier la configuration et que vous puissiez facilement la tester sur vos blogs/sites personnels, j’ai choisi de réunir les deux briques (Web + Supervision) sur une même machine.
C’est la question que j’ai posé sur Twitter il y a quelques jours et j’ai reçu un grand nombre de réponses allant toutes dans le même sens. Faute de temps, je n’ai pas pu exploiter toutes les pistes mais je garde cela sous le coude et je ferai sûrement évoluer ce billet dans le futur.
J’ai donc découpé la supervision en deux groupes de services: système / web.
Pour les services système:
Pour les services Web:
Cette liste est bien sûr très restrictive, j’attend vos idées dans les commentaires !
L’idée est de fournir les configurations « brutes de décoffrages ». Si vous avez des problèmes pour appliquer cette configuration sur votre serveur, je vous conseille de consulter les billet de la page sur la supervision de ce blog.
La configuration des services système:
[cce]
# Define a service to check the disk space of the root partition
# on the local machine. Warning if < 20% free, critical if
# < 10% free space on partition.
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Root Partition
check_command check_local_disk!10%!5%!/
}
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Backup Partition
check_command check_local_disk!10%!5%!/mnt/backup
}
# Define a service to check the number of currently logged in
# users on the local machine.
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Current Users
check_command check_local_users!2!3
}
# Define a service to check the number of currently running procs
# on the local machine. Warning if > 250 processes, critical if
# > 400 processes.
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Total Processes
check_command check_local_procs!250!400!RSZDT
}
# Check memoire avec script check_memory
# https://blog.nicolargo.com/2008/07/surveiller-la-memoire-de-vos-serveurs-avec-nagios.html
# -w 5% -c 1%
define service{
use local-service
host_name localhost
service_description Memory
check_command check_mem!10%!5%
}
# Define a service to check the load on the local machine.
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Current Load
check_command check_local_load!5.0,4.0,3.0!10.0,6.0,4.0
}
# Define a service to check the swap usage the local machine.
# Critical if less than 10% of swap is free, warning if less than 20% is free
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Swap Usage
check_command check_local_swap!20!10
}
# Check RAID (hardware)
define service{
use local-service ; Name of service template to use
host_name localhost
service_description RAID1
check_command check_raid
}
[/cce]
puis les services Web:
[cce]
# Define a service to check SSH on the local machine.
define service{
use local-service ; Name of service template to use
host_name localhost
service_description SSH
check_command check_ssh
#notifications_enabled 0
}
# Varnish process
# /usr/lib/nagios/plugins/check_procs -w 2:2 -c 1:1024 -C varnishd
define service{
use local-service
host_name localhost
service_description Varnish process
check_command check_local_process!2:2!1:1024!varnishd
}
# Check process
# /usr/lib/nagios/plugins/check_procs -w 5:5 -c 1:1024 -C nginx
define service{
use local-service
host_name localhost
service_description Nginx process
check_command check_local_process!5:5!1:1024!nginx
}
# Define a service to check Varnish
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Varnish access
check_command check_url!http://localhost/
}
# Define a service to check HTTP on the local machine.
define service{
use local-service ; Name of service template to use
host_name localhost
service_description Nginx access
check_command check_url!http://localhost:8080/
}
# Define a service to check HTTP on the local machine.
define service{
use local-service ; Name of service template to use
host_name localhost
service_description URL Blog check
check_command check_url!http://www.mondomaine.com/
}
# Define a service to check URL
# http://www.mondomaine.com/googleXXXXXXXX.html
define service{
use local-service
host_name localhost
service_description URL Google check file
check_command check_url!http://www.mondomaine.com/googleXXXXXXXXXX.html
service_dependencies localhost,HTTP Blog
}
# Define a service to check URL
# https://blog.nicolargo.com/sitemap.xml.gz
define service{
use local-service
host_name localhost
service_description URL Sitemap
check_command check_url!http://www.mondomaine.com/sitemap.xml.gz
service_dependencies localhost,HTTP Blog
}
# Define a DDOS detection service
# https://blog.nicolargo.com/?p=4100
# Warning: >50 SYN_RECV
# Critical: >70 SYN_RECV
define service{
use local-service
host_name localhost
service_description DDOS detect
check_command check_ddos!50!70
}
[/cce]
Et voilà ce que cela donne dans mon Shinken/Thruk:


 Sur ma Dedibox DC, je dispose en standard de deux disques dur fonctionnant en RAID1 grâce à une carte hardware. Comme le mirroring entre les deux disques est effectué directement depuis la carte hardware, il faut effectuer quelques manipulations au niveau du système d’exploitation pour avoir un état du RAID1.
Sur ma Dedibox DC, je dispose en standard de deux disques dur fonctionnant en RAID1 grâce à une carte hardware. Comme le mirroring entre les deux disques est effectué directement depuis la carte hardware, il faut effectuer quelques manipulations au niveau du système d’exploitation pour avoir un état du RAID1.
On commence par trouver le nom de la carte qui se charge du RAID.
[cc lang= »bash »]
# lspci
01:00.0 Serial Attached SCSI controller: LSI Logic / Symbios Logic SAS2008 PCI-Express Fusion-MPT SAS-2 [Falcon] (rev 03)
[/cc]
On ajoute ensuite le dépôt suivant pour prendre en charge les utilitaires pour la carte Fusion-MPT SAS-2:
Dans un terminal root, il faut saisir la commande suivante:
[cce lang= »bash »]
echo « deb http://hwraid.le-vert.net/debian squeeze main » > /etc/apt/sources.list.d/hwraid.list
[/cce]
Puis mettre à jour ses dépôts et installer le logiciel dédié à cette carte:
[cc lang= »bash »]
apt-get update
apt-get install sas2ircu
[/cc]
Pour avoir la liste des cartes RAID de son système:
[cc lang= »bash »]
# sas2ircu LIST
LSI Corporation SAS2 IR Configuration Utility.
Version 5.00.00.00 (2010.02.09)
Copyright (c) 2009 LSI Corporation. All rights reserved.
Adapter Vendor Device SubSys SubSys
Index Type ID ID Pci Address Ven ID Dev ID
—– ———— —— —— —————– —— ——
0 SAS2008 1000h 72h 00h:01h:00h:00h 1028h 1f1dh
SAS2IRCU: Utility Completed Successfully.
[/cc]
L’information intéressante est le numéro de la carte (0 dans mon cas) qui va servir pour la commande suivante qui va afficher l’état des disques RAID:
[cc lang= »bash »]
# sas2ircu 0 DISPLAY
LSI Corporation SAS2 IR Configuration Utility.
Version 5.00.00.00 (2010.02.09)
Copyright (c) 2009 LSI Corporation. All rights reserved.
Read configuration has been initiated for controller 0
————————————————————————
Controller information
————————————————————————
Controller type : SAS2008
BIOS version : 7.11.01.00
Firmware version : 7.15.04.00
Channel description : 1 Serial Attached SCSI
Initiator ID : 0
Maximum physical devices : 39
Concurrent commands supported : 2607
Slot : 1
Segment : 0
Bus : 1
Device : 0
Function : 0
RAID Support : Yes
————————————————————————
IR Volume information
————————————————————————
IR volume 1
Volume ID : 79
Status of volume : Okay (OKY)
RAID level : RAID1
Size (in MB) : 953344
Physical hard disks :
PHY[0] Enclosure#/Slot# : 1:0
PHY[1] Enclosure#/Slot# : 1:1
————————————————————————
Physical device information
————————————————————————
Initiator at ID #0
Device is a Hard disk
Enclosure # : 1
Slot # : 0
State : Optimal (OPT)
Size (in MB)/(in sectors) : 953869/1953525167
Manufacturer : ATA
Model Number : WDC WD1003FBYX-1
Firmware Revision : 1V02
Serial No : WDWCAW31480098
Protocol : SATA
Drive Type : SATA_HDD
Device is a Hard disk
Enclosure # : 1
Slot # : 1
State : Optimal (OPT)
Size (in MB)/(in sectors) : 953869/1953525167
Manufacturer : ATA
Model Number : WDC WD1003FBYX-1
Firmware Revision : 1V02
Serial No : WDWCAW31419175
Protocol : SATA
Drive Type : SATA_HDD
————————————————————————
Enclosure information
————————————————————————
Enclosure# : 1
Logical ID : 5782bcb0:32624a00
Numslots : 8
StartSlot : 0
Primary Boot Slot : 0
————————————————————————
SAS2IRCU: Command DISPLAY Completed Successfully.
SAS2IRCU: Utility Completed Successfully.
[/cc]
On peut voir l’état du disque RAID ainsi que celui des disques physiques (slot 0 et slot 1).
Pour effectuer une vérification rapide du RAID1, c’est à dire que les deux disques sont fonctionnels, il suffit de sasir la commande suivante:
[cc lang= »bash »]
# sas2ircu 0 STATUS
LSI Corporation SAS2 IR Configuration Utility.
Version 5.00.00.00 (2010.02.09)
Copyright (c) 2009 LSI Corporation. All rights reserved.
Background command progress status for controller 0…
IR Volume 1
Volume ID : 79
Current operation : None
Volume status : Enabled
Volume state : Optimal
Physical disk I/Os : Not quiesced
SAS2IRCU: Command STATUS Completed Successfully.
SAS2IRCU: Utility Completed Successfully.
[/cc]
La ligne suivante:
Volume state : Optimal
permet d’identifier un fonctionnement nominal.
Il ne reste plus qu’à intégrer cette commande dans un nouveau plugin Nagios/Shiken pour superviser l’état de votre RAID1 (cela sera surement le sujet d’un prochain billet).
Source: Forum Online.net
Comme je l’annonçais il y a quelques jours dans ce tweet…

…je suis finalement retourné à Gnome 2 sur mon portable perso (sous Ubuntu 11.04) qui me sert pour surfer et bloguer à la maison.
J’en avait vraiment marre d’Unity. J’ai essayé quelques mois mais la mayonnaise ne prend pas… peut être les prémisses de la vieillesse de mon coté. Bientôt la cure de cranberry contre l'incontinence… Sérieux. J’avais la désagréable impression d’avoir dans les mains un système non finalisé.
Voici donc mon desktop Ubuntu 11.04 avec le bon vieux Gnome 2:

Pour installer le thème Conky Orange, il faut bien sur dans un premier temps installer Conky sur votre système (en cliquant directement ici si vous êtes sous Ubuntu) ou en suivant la documentation Ubuntu-fr.
Ensuite, il suffit de saisir les commande suivante dans un terminal:
[cc lang= »bash » width= »580″]
wget http://gnome-look.org/CONTENT/content-files/137503-conky_orange.zip
unzip 137503-conky_orange.zip
mkdir ~/.conky/
cp conky_orange/* ~/.conky/
mv ~/.conkyrc ~/.conkyrc.old
ln -s ~/.conky/conkyrc_orange ~/.conkyrc
[/cc]
Je reviens à du très simple:
Et vous ? Cela donne quoi ?
A vous de nous montrer vos écrans
(par exemple en utilisant yFrog puis en partagant l’URL) !
 Salut Jean et merci de nous consacrer un peu de ton temps pour répondre à mes questions et à celles des lecteurs du blog.
Salut Jean et merci de nous consacrer un peu de ton temps pour répondre à mes questions et à celles des lecteurs du blog.
On commence tout de suite !
—
Peux tu présenter Shinken en quelques lignes ?
Shinken est un outil de supervision, une implémentation de Nagios en Python ‘from scratch’ qui a pour objectifs principaux de simplifier la vie des administrateurs de grands parcs et de coller au mieux à l’évolution de l’IT des dix dernières années, et si possible préparer les dix prochaines…
Pourquoi t’es tu lancé dans une t’elle aventure ? Quelles sont tes sources de motivation ?
En fait Shinken est un incident industriel !
Il commence sa vie sans nom et peu de temps après la fin de l’écriture de mon livre “Nagios 3” (editions Eyrolles). Pour ce dernier, j’avais passé une bonne part de mes recherches sur les chapitres de performances et d’environnements distribués. Ceci m’avait permis de voir les limites de Nagios dans le domaine. Pour simplifier, Nagios était parfaitement adapté à un parc de taille moyenne (200 serveurs) mais commençait à avoir du mal au dessus de par son architecture « mono daemon » et quelques défauts d’implémentations. Il ne faut pas lui lancer la pierre non plus, sa conception remonte à plus de 10 ans pour justement régler la supervision d’un tel parc, et n’a gère évolué depuis.
Je me suis donc lancé dans un « proof of concept » qui tentait de corriger dans un premier temps les problèmes de performances. Ceux-ci étaient plutôt simple à analyser au final :
Je suis un grand fan de Python, principalement pour sa syntaxe claire et son état d’esprit (lire le “zen of Python” pour plus d’info là dessus, ceci résume très bien le “Python”). Il y avait justement une librairie pour avoir des pool de processus, je me suis dit qu’un petit script qui vérifie que le concept de pool n’était pas aberrant, et que ceci me prendrait bien moins de temps que la même chose dans le code de Nagios qui n’est pas d’une toute première fraîcheur en terme de lisibilité, même pour du C, sur cette partie.
A l’époque, ce proof of concept n’avait pas pour objectif d’être publié. Mais je me suis rapidement retrouvé confronté à une surprise que je n’attendais pas : j’obtenais des performances excellentes, bien meilleures que ce que produisait Nagios. Piqué dans ma curiosité, j’ai donc voulu valider cela en mettant un peu les deux à égalité : en mettant les algorithmes d’ordonnancement et par implication la lecture de la configuration. Deux points qui allaient se révéler être les deux choses les plus complexes à coder dans ce projet.
Je me suis rendu compte de bug dans Nagios dans l’ordonnancement à ce moment là d’ailleurs (et qui est toujours présent d’ailleurs dans Nagios et Icinga) ce qui ne m’étonne gère quand je vois la taille réduite du code de Nagios sur cette partie, et ce que ceci m’a demandé en Python (5 fois plus de lignes de codes Python environs, et 1 mois entiers de prise de tête sur des algorithmes de calculs de date…). Au final, là encore, les performances étaient au rendez-vous.
Je décide donc de prévenir les auteurs de Nagios. Je n’ai pas eu de réponse de l’auteur principal, mais une un peu évasive et peu convaincue d’un des coauteurs. Je décide donc de continuer et tenter de régler les soucis d’architectures distribuées. J’ai donc commencé à concevoir ce qu’était pour moi l’architecture idéale. J’ai donc “découpé” mon daemon en plusieurs morceaux au fil du temps, l’architecture n’étant pas arrivé en ce qu’elle est du jour au lendemain 🙂
L’un de ces découpage permet LA fonctionnalité de Shinken à l’époque : le découpage intelligent de configuration pour la disperser suivant les “ressources” de supervision. Ceci a aussi donné le nom au projet, un Shinken étant un katana utilisé dans la guerre car il est le plus coupant (puis le nom sonnait bien 🙂 ). Je propose d’ailleurs au passage cet algorithme de découpage à d’autres projets, mais il ne les intéresse pas.
Je publie de code pour demander des avis et j’ai ma première contribution d’un autre auteur de livre Nagios, un allemand nommé Gerhard Lausser , qui deviens co-leader naturel du projet de part sa forte implication. Là arrive un dilemme : notre outil fonctionne très bien, gère 90% du boulot de Nagios, est performant et codé de manière très modulaire. Mais backporter le code en C prendrait un temps monstrueux, surtout quand on regarde le peux de temps de développement alloué au core Nagios par ses auteurs déjà à l’époque. Je demande ainsi s’il serait envisageable d’avoir une branche “Nagios 4”” qui permettrait à notre code de mûrir et aux auteurs de prendre la main et faire en sorte d’une migration entre l’ancienne implémentation et la nouvelle se fasse e la manière la plus douce possible, même si elle doit prendre 2 ou 3 ans. Pas de réponses, donc je décide de monter d’un niveau et je fais la même proposition sur la mailing list Nagios-devel. Là, toujours pas de réponse de la part de l’auteur de Nagios, mais un échange avec un des co-auteur (le même que la première fois, qui est une personne bien plus ouverte que ses collègues au final) qui tourne malheureusement au troll sur les langages car il ne voyait pas à l’époque d’un bon oeil le Python, comme bon nombres d’autres codeurs C.
N’arrivant pas à obtenir une réponse de l’auteur principal (que j’attends toujours, enfin une vraie, pas un FUD sur la licence utilisée…), et n’arrivant pas à convaincre du bien fondé de cette branche et de ce code, je décide de monter le projet Shinken comme indépendant de son grand frère. Le drôle de fork est fait, un peu à contre coeur à l’époque.
Mes sources de motivations étaient au tout début l’amusement et les défis techniques (je suis particulièrement fier du calcul de la date de checks pour tous les cas de timeperiod par exemple 🙂 ). Puis quand c’est devenu plus sérieux et que ça pouvait régler mes soucis au travail (je suis admin d’un parc de 300 serveurs dispersés sur 50 filiales de par le monde environs) je me suis dit que ça pouvait intéresser d’autres personnes, ce qui fût réellement le cas :).
Désormais je crois plus que jamais à ce projet, et j’aimerai pourquoi pas qu’il prenne un part plus importante dans mon activité professionnelle, comme pour des activités de consulting ou de formations par exemple à moyen terme (étant un heureux papa de deux petits bouts je ne peux me permettre de me lancer à cours terme dans une telle activité).
Développes tu Shinken seul ? As tu des contributeurs réguliers ?
Je suis le responsable d’une majorité de lignes de codes, et donc de bugs en effet. Mais je ne suis pas seul heureusement. Côté codeurs, Gerhard qui fût l’un des premiers contributeurs externes est désormais co-leader du projet et code régulièrement. Il est même maître sur certains modules importants comme celui qui permet à Thruk ou PNP (métrologique) d’obtenir leurs informations. Nous avons également eu le soutient d’un autre codeur allemand qui papillonne d’un projet à un autre, mais qui nous a bien aidé à nettoyer le code à une époque, ainsi qu’un autre codeur qui est un spécialiste du refactoring/nettoyage et de la recherche de bugs (salut Greg) 🙂 Nous avons également l’aide ces derniers temps d’un codeur d’UI, nommé Andreas, qui nous aide grandement sur ce nouveau domaine auquel nous ne sommes pas trop habitués 🙂
Mais les codeurs ne font pas tout, loin de là. Quelques personnes nous aide sur les forums pour répondre aux utilisateurs, écrire/corriger la doc (coucou Seb, Denis et Remi 🙂 ), tester de nouvelles fonctionnalités, dessiner le logo (salut Romu), faire des packages pour les distributions principales ou écrire des scripts d’installations ;). Ceci nous aide encore plus qu’un patch car se sont des tâches très ingrates du point de vue “codeur”, mais qui est pourtant l’un des aspect les plus cruciaux pour la réussite d’un projet! Je tiens donc à les remercier du font du coeur, car un projet c’est avant tout une communauté avant d’être des lignes de codes. Ils sont la vraie force de ce projet qui tente d’être le plus ouvert possible.
Quels sont pour toi les trois principaux points forts de Shinken par rapport à Nagios Core ?
Pas simple de répondre à cette question… On pourrait s’attendre à ce que je dise son architecture distribué, mais en fait ceci n’arrive qu’en 4ième position (même si pour certains confrontés à des soucis de performances il va naturellement remonté en première ligne dans leur cas).
Dans l’ordre :
Le premier permet aux administrateurs d’un grand parc de se concentrer sur ce qui est “important”. Hors à notre époque de ressources humaines limitées, c’est plus que nécessaire.
Le second est souvent sous estimé, mais il est pourtant crucial dans le futur succès du projet. Nous avons vu que Nagios était orienté pour les infra de taille moyenne. Or Shinken lui couvre tout le spectre : moyen; haut avec le distribué mais également tout petit parc qui n’ont souvent pas d’admin Linux sous la main et seulement un serveur Windows à disposition.
Le dernier est tout simplement naturel pour moi, je ne saurai fonctionner autrement, mais le succès d’un projet passe par son ouverture. Il n’y a qu’a voir une preuve en regardant le déclin de Nagios : c’est plus un problème humain d’un projet qui n’avance plus dans son ensemble que technique qui est en est la cause.
Et les trois points faibles ?
Quels sont les raisons que tu peux mettre en avant pour convaincre une DSI de changer de solution de supervision et de se tourner vers Shinken ? (question de Guillaume Reynaud du blog Quick Tutoriel)
Un outil de supervision est là pour aider les admis à garder les services pour les utilisateurs en état de fonctionnement. Dis comme ça c’est simple, mais en fait si c’était simple à atteindre il y a 10ans (quelques dizaines de serveurs tout au plus, des services infra qui avait une vue “pure IT” – non business – et des services rarement en cluster) avec des outils comme Nagios n’est plus possible efficacement.
Un service qui tombe est désormais directement converti en monnaie sonnante et trébuchante par le directeur financier. Or nous avons désormais une vue plus “business” qu’IT, des parcs de plus en plus large, de nombreuses couches d’abstractions (qui a dit virtualisation?), multiplication des serveurs et des services et des contracts de services sur la tête (arriver à ce moment là de la conversation, le DSI devrait être plus réceptif déjà, car ce sont des soucis qu’il a tous les jours).
Shinken est justement pensé pour cela : monté en charge sans soucis, notion dans le core de la criticité d’une application, de la notion de cluster, de la corrélation et ainsi arriver à une chose si simple à expliquer, mais si dure à obtenir : faire en sorte que les admins puissent se concentrer en priorité sur les problèmes sources qui impactent des services importants pour le business. Nagios se “vends” lui même comme un outil de supervision “IT”. Ceci n’est plus suffisant. Faut dépasser la vision pure IT, et passer au niveau “business”, car c’est ça que l’on attend les services informatiques désormais. Leur solution de supervision doit suivre logiquement. (ici, le DSI doit être plus réceptif, donc l’achever avec les gains apportés par la métrologie, sortir une carte ou deux de Nagvis, et c’est gagné).
En réaction à l’orientation très fermée du développement de Nagios Core, on voit fleurir de nombreux forks. Tu arrives donc dans un marché très concurrentiel…
Oh que oui ! D’un certain côté tant mieux, ceci laisse le choix à l’utilisateur, mais le risque réside dans la fragmentation de la communauté en plusieures bien moins fortes. Ceci est une part du dilemme qui m’a animé avant de publier Shinken en tant que projet à part entière. Mais j’ai pensé que même si le projet n’arrivait pas à s’imposer, au moins il aurait été un « proof of concept » géant sur où il fallait aller dans la supervision à mes yeux.
Au final, il semble bien prendre et j’en suis très heureux. On voit encore fleurir les forks, come celui dernièrement de Centreon, mais je pense que l’écosystème va jouer son rôle, et va sélectionner les meilleurs projets. Qui sait, peux être que Nagios sortira grand vainqueur (même si j’en doute fortement)? Qu’Icinga amènera de vraies avancées, que quelqu’un arrivera à comprendre l’architecture de Merlin ou que le couple Centreon-engine/Centreon-Broker raviera cette première place?
Un risque fort réside dans le fait d’avoir des coeurs “presques compatibles”, un peu comme un HTML à la mode IE6, le tout poussé par des besoins business des différents intervenants qui n’auraient plus d’intérêt à coopérer. Il ne faut pas oublier que des solution comme Zabbix montent aussi au créneau et réclame cette première place d’outil de supervision du monde Open Source. Bien malin sera celui qui saura ce que va donner cet Opéra joué par des musiciens qui on leur propre partition à jouer. Espérons seulement qu’un chef d’orchestre se révèle et que la musique reprenne une certaine harmonie. Ce vote se faisant par les utilisateurs, il sera sage et justifié. C’est après tout l’un des principal avantage de notre écosystème “Open Source” tant concurrentiel et sans merci !
Pour un utilisateur connaissant bien Nagios, quel est l’investissement en temps pour switcher vers Shinken ?
Pas énorme. Disons une matinée pour l’installation propre et comprendre le fonctionnement global. Puis une après-midi pour mettre en place son premier environnement distribué/hautement disponible complet en suivant le tutorial. Beaucoup d’efforts on étés fait pour que la migration se passe de la manière la plus douce possible, comme la génération automatique de certains modules par exemple. En ce qui concerne les fonctionnalités avancées comme les règles business et les notion d’impact business, on rajoutera une matinée supplémentaire, pas tant dans l’écriture, mais surtout dans ce que ceci implique en matière de supervision 🙂
Une petite remarque par contre : pour un utilisateur ne connaissant pas Nagios, il y a toujours un certain temps d’adaptation qui ne diffère pas trop de Nagios. Comme par exemple comprendre les concepts de supervision (que beaucoup passent bien trop rapidement à mon goût) et les différentes sondes. Vous pouvez rajouter tous les outils de découverte que vous voulez (comme celui dans Shinken 🙂 ), ces phases seront toujours importantes pour pleinement utiliser l’outil à sa juste valeur. Un outil de supervision mal maîtrise fait plus de mal que de bien. Cette phase est donc cruciale et mérite un certain investissement qui sera rentabilisé par centuples plus tard 🙂
Quels sont les principaux avantages de Shinken par rapport à une solution comme Centreon ? (question de Guillaume Reynaud du blog Quick Tutoriel)
Exactement les mêmes que par rapport à Nagios, Centreon apportant une UI, certe pratique, mais qui ne révolutionne pas la conception de la supervision. Shinken avec son système avancé de corrélation, règles business et notion d’importance si (enfin il essaie au moins). Ce sont des choses qui aident les admins et leurs chefs dans leur vie de tous les jours, bien plus qu’un nouveau style CSS. Ceci sera vu un peu plus loin d’ailleurs.
Il faut voir par contre que Centreon est une solution complète, alors que Shinken est un outil, une brique de base. Centreon offre par exemple une gestion très pratique des traps SNMP ou son propre service de reporting.
Heureusement, les deux ne sont pas antinomiques, et il est possible, mais non trivial, de les faire dialoguer. C’est d’ailleurs ce que j’ai encore en production. Ceci grèvera cependant les possibilités de Shinken, comme par exemple la définition des règles business ou encore les notions d’importance business (des patchs “hacks” sont en cours pour Centreon 2.4). Mais qui sait, si la demande envers le projet Centreon se fait pressante, on peux espérer un support plus important de Shinken dans ce dernier, même si il faut bien le reconnaître que l’arrivée récente de centreon-engine ne va pas dans ce sens.
De part son architecture, Shinken offre nativement une supervision distribuée hautement disponible (contrairement à d’autres outils de supervision open-source),penses tu que cette fonctionnalité fait de shinken un outil a n’utiliser que sur des grandes architectures de système d’information ? (question d’Anthony Paradis modo du forum de Monitoring-FR)
Je ne pense pas, car justement je ne mettrait pas l’architecture dans la top 3 de ses avantages.
Une petit société avec 10 serveurs sous Windows sera bien contente d’avoir son système de supervision sur cette même plate forme, et mettre facilement un backup en place sur un second.
Une de taille moyenne sera contente d’enlever un serveur physique Nagios et mettre une machine virtuelle Shinken à la place grâce au gain de performances. Ils seront content également d’avoir un outil qui fait la liaison de dépendance automatique des VM et des hôtes pour eux, avec le support des migrations de machines virtuelles d’un hôte à un autre sans avoir à toucher quoi que ce soit.
Passons à l’actualité, la version (0.8 aka Guilty Gecko) sort dans quelques semaines. Mise à part les classiques corrections de bugs, quelles sont les nouvelles fonctions ?
Comme vu dans la dernière release, les aspects d’architectures sont finis, donc pas de grosse annonce de ce côté là. Cette version sera d’ailleurs la 0.8 et non la 0.7 car Shinken est déjà en production à plusieurs endroit sans soucis, donc il est temps d’accélérer un peu le mouvement vers la 1.0 qui devrait être pour la fin de l’année si tout va bien, et qui sera un signal fort sur la stabilité du projet.
Cette 0.8 aura donc principalement :
A cours terme, quelles orientations penses tu donner à Shinken ?
Je pense qu’il faut dépasser la vision d’outil et se diriger vers la solution de supervision.
Combien d’administrateurs ont encore le temps de devenir des experts dans la supervision et monter leur propre solution à base de Shinken ou Nagios à la main ? Combien d’administrateurs sous Windows attendent un outil de supervision simple à mettre en place et sans prix exorbitant de licences ?
Les administrateurs d’aujourd’hui ne sont plus des barbus qui recompilent tous leurs outils, même si ceci m’attriste un peu il faut bien l’avouer (j’ai une capillarité limitée mais je suis un barbu dans l’âme 🙂 ). Mais c’est un fait, désormais nous mettons en place des solutions, non plus des outils. Nous devons nous concentrer sur les services rendus aux utilisateurs et arrêter de ne penser qu’à l’IT ‘infra’. On ne fait plus une infra avec des briques qui sont de simples outils, mais avec des briques qui sont elles mêmes des solutions.
Ce n’est pas pour rien que Zabbix a un succès grandissant : c’est rapide à mettre en place et l’utilisateur n’est pas perdu. Je ne suis pas un fan du fonctionnement “supervision” de Zabbix que je ne trouve pas assez flexible pour les modèles de corrélations (et donc source de tempêtes d’alertes, qui est l’ennemi juré en supervision), mais il a une grande qualité que l’on ne peux pas lui renier : on le met en place rapidement et “ça marche”.
Ceci n’empêchera pas Shinken de pouvoir être utilisé comme une simple brique d’une autre solution plus grosse de type Centreon, il est hors de question de casser ce côté modulaire et le core actuel continuera d’être utilisable seul bien évidement.
On reproche souvent à Nagios le manque d’ergonomie de son interface utilisateur (UI) basée sur des standards/technologies Web dépassés. Actuellement, Shinken utilise des UI externes (comme Thruk) qui copient plus ou moins cette dernière. A ton avis quelle est l’interface graphique permettant d’exploiter au mieux Shinken? (question de David Paugam du Groupe Asten)
Il est vrai que les technologies de l’UI de Nagios sont des hérésies à l’heure actuelle (CGI en C qui parse un gros fichier plat, tout ce qu’il ne faut pas en gros). Mais ce qui m’embête bien plus c’est son ergonomie et surtout la vision de la supervision qu’elle propose et le peux de service qu’elle rends à l’utilisateur au final. On mettrait un convertisseur XSL vers HTML en partant du fichier de status que l’on obtiendrait quelque chose de similaire.
Et ceci est le même constat pour les autres interfaces de visualisation (Thruk, Ninja, Centreon, Icinga 1.0 ou 2.0 ou alors MK/Multisite). Si on prends un peu de recul, que l’on enlève les jolis styles CSS et les bouts de javascript de certaines qu’est ce qu’elles proposent ?
Et bien les mêmes vues ou presque. Elles nous proposent toutes des vues ‘IT mode infra’ à la sauce CGI. On a donc le droit à une liste longue comme le bras d’éléments orange ou rouge sans aucun ordre (il est inutile de montrer du vert à un admin, le vert c’est réservé aux chefs 🙂 ). Or à l’heure actuelle on a pour un même service rendu aux utilisateurs au moins 3 environnements : DEV, QUALIF et PROD. Or lequel est important ? PROD. Le reste c’est à traiter après les autres.
De même, un service comme un ERP est plus important qu’un outil pour emprunter des DVD au CE. Il est donc crucial que l’administrateur se focalise en priorité sur ce qui est important pour le business, ca c’est ça qui le paye à la fin du mois !
Autre chose, nous avons maintenant des services qui se composent de clusters qui reposent sur des infras à X niveaux (au minimum Web frontaux, BDD, répartiteurs Web, serveur disque, serveurs ESX de virtualisation, baie de disque et toute la partie réseaux ethernet ou SAN bien entendu). Si un élément “pur infra” comme un switch tombe, tout le reste part avec lui, sur tous les services, sur tous les environnements. Vous allez donc avoir une part importante de votre infra en rouge vive sur votre console. Or une seule info importe pour l’administrateur : quel est l’élément source qui m’a causé tout ça ? Le reste est bon à mettre à la poubelle, c’est l’unique info qui importe à l’admin. Son chef lui voudra les mêmes infos mais dans un sens de recherche opposé : quels services sont tombés et pourquoi ?
Or, les outils ci-dessus n’aident en rien à cela. Il n’y a pas de priorisation des éléments, pas de visualisation de la corrélation faite au seins de l’outil, sous forme de graph ou autre. Et ceci en mettant de côté les vues “opposées” des admins et des responsables d’infra qui ne peuvent pas avoir les mêmes vues, car leurs manière de voir les choses est diamétralement opposée !
La seule UI qui a innovée ces dix dernières années dans ce sens c’est NagVis ! J’ai intégré quelques vues en ce sens dans Thruk en début d’année, mais ça n’a pas trop pris et on reste toujours avec la même philosophie qu’il y a 10 ans, ce que ne cache pas l’auteur de Thruk. Il conviendra parfaitement aux administrateurs qui n’ont pas/(pas besoin d’) un point de vue “business”. Pour les petits sites, MK/Multisite est très “joli”, mais est très lié à l’agent check_mk, et peux être considéré comme une solution à part entière, mais sans la partie modulaire par contre.
Reste le problème de la configuration. Là Centreon se pose encore en grand maître des lieux, mais n’est pas adapté à Shinken et va fortement limité son intérêt. Les autres solutions graphiques de configuration souffrent du même problème actuellement, il n’y a donc pas de solution miracle malheureusement à l’heure actuelle…
Souhaites tu intégrer une UI propre à Shinken ?
La réponse est oui !
En fait, j’ai tenté ce que j’ai pu pour l’empêcher, mais le fait est là : la vision problème source/ impact / criticité du coeur de Shinken n’est pas encore prise en compte par les interfaces. Quand le coeur de Shinken n’était pas encore fini à mon goût, je ne voulais pas lancer un projet qui aurait canibalisé nos forces.
J’ai donc tenté de motiver le projet Thruk qui a bien accepté mes patchs malgré mon Perl catastrophique (en même temps ça reste du Perl, ça se trouve il est très beau pour du Perl…), mais l’interface reste à dominance “old school” car elle plait ainsi à beaucoup d’anciens utilisateurs de l’ancienne CGI.
L’auteur de MK/Multisite n’est pas des plus ouverts à mes idées et mes tentatives de présentations de ma vision de la supervision auprès de Centreon n’a pas eu beaucoup d’effet et n’a pas dû convaincre car désormais nous avons un fork de Nagios en plus 🙂
Je me trompe peux être, mais je suis convaincu que mettre en avant la corrélation, la priorisation et tout ce qui va avec la vision “business” facilitera grandement le travail des admins et des responsables d’infrastructure.
Mon objectif est d’arriver à une UI qui permettra de dire simplement à :
Avec de l’aide d’un designer web, nous nous sommes lancés dans des mockups d’interface qui ne ressemblent pas vraiment à ce qui existe actuellement, tant sur le fond (UI sans BDD ni requêtes, assez original non?) que surtout sur la forme qui se veut très “user-friendly”, avec très peu de vues, mais très étudiées et utiles (80% des utilisateurs restent toute leur vie dans 20% des pages, gagnons du temps, ne faisons que 20% des pages).

Un bon indicateur de succès sera si les utilisateurs considèrent cette interface comme le “gnome” des interfaces de visualisation de supervision, reléguant les autres aux rang de WindowMaker. Elle ne remplacera pas un Thruk ou un Centreon chez les plus barbus d’entre nous, les vrais qui tournent en gentoo, changent les options de compilation de GCC pour gagner 0.5% de perf et ne voient pas l’intérêt des tablettes graphiques dans le monde de demain… Mais j’arriverai à vivre avec ça 🙂
Cette UI intégrera t’elle un outil de génération de rapports dont les DSI sont très ( voir trop) friand ?
Pas dans un premier temps et ce pour trois raison :
Et des fonctions d’édition en ligne des fichiers de configurations ? (question de David Paugam du Groupe Asten)
Cela sera l’étape intermédiaire avant le reporting en effet, et devrait être consommatrice de temps. Mais je doute dans ce cas de l’édition “in line” en fichiers textes. Outils de configuration + fichiers plats ne font pas bon ménage à mon goût. Une “base” de configuration serait plus adaptée, mais je n’ai pas poussée la réflexion bien plus loin.
Sera t’elle compatible pour une utilisation mobile depuis les smartphones ou comptes tu faire développer des applications dédiées (iPhone et Android) ? (question de Nicolas Ledez du blog Le bazar de Nicolas)
Alors là c’est simple : j’ai une vision bien plus gentille avec les designers d’UI depuis que j’ai une tablette graphique et que j’ai regardé mon fils de 2ans l’essayer. Il l’utilise sans que je lui explique. Je me suis donc penché un peu plus sur ce domaine qui désormais me fascine, car l’ergonomie est quelque chose que j’avais en tête en pensant à celle de Shinken mais qui m’a permis d’avoir des exemples concrets de ce qu’il faut faire, et ne pas faire.
L’interface sera ainsi bien plus proche d’une interface “smartphone” que d’une UI classique d’un outil d’administration, ce qui explique pourquoi elle ne vas pas plaire à tout le monde également. Donc pas de soucis, les tablettes et smarphones sont prévus 🙂
D’un point de vue technique, je ne vois pas l’intérêt de l’application native quand on a toutes les possibilités d’HTML5 sous la main et que l’on n’a pas besoin de prendre en photo son utilisateur.
Il est donc à prévoir d’ailleurs une non-compatiblilité avec IE6 ou 7, et là clairement ils ne sont pas dans le cahier des charges. Je ne serai pas contre un patch (non intrusif…) qui permettrait de les supporter, mais ces navigateurs étant tellement mal faits et limitatifs dans l’interface qu’il serait non efficace de tenter de les gérer.
Quel logiciel de métrologie conseilles tu en parallèle de Shinken ? (question de David Paugam du Groupe Asten)
PNP4 Nagios. C’est un très bon outil qui a d’ailleurs son propre module depuis Shinken. Celui de Centreon est pas trop mal non plus, mais est plus consommateur de perfs.
Je ne suis pas trop pour un Cacti en parallèle d’un outil de supervision, car on aura tendance à demander à ce dernier de rechercher l’information lui même (par exemple en SNMP) alors que l’on a déjà effectué une telle demande dans un agent de supervision. Ce n’est pas trop du point de vue charge machine ou réseaux que ceci m’embête, mais bien d’un point de vue conceptuel où on fait deux fois la même chose, et où l’admin va devoir gérer deux agents et configurations, ce qui est totalement injustifié quand on a un PNP qui peux faire tout aussi bien que Cacti par exemple.
Shinken est développé en langage Python. Quels sont pour toi les avantages de ce langage par rapport au langage C dont Nagios Core est issu ? Une vue extérieure pourrait penser que le Python est moins performant que C, surtout pour des applications proches des couches systèmes et réseaux.
J’avais le même a priori il y a quelques années. J’ai été élevé à l’assembleur et au C, avec de l’Emacs et du Makefile fait à la main (je n’ai pas tourné barbu pour rien hein…). Même si j’avais bien vu l’intérêt de l’orienté objet pour la création d’UI (modèle MVC + orienté objet = moins de code, moins de bugs), mais pas dans le domaine très “noble” des daemons serveurs.
J’ai aussi été bassiné pendant de longues années par des algorithmes au nom impossible à retenir (Disjtra, je suis désolé, j’adore ton algo, mais alors ton nom….) mais qui faisaient toute la différence dans ce que le développeur mettait comme “intelligence” dans son code (bien plus que de joli commentaires ou des lignes de 80 caractères au maximum). Les algos allant bien évidement avec la recherche de leur efficacité en O(1) si possible, O(n) dans de nombreux cas, et O(n*…*n) si on s’y était mal pris.
Je n’avais jamais fait le lien entre les deux. Pour moi la performance allait tout d’abord au langage choisi (plus c’est bas niveau, plus c’est rapide) puis le reste. Or c’est totalement faux, et c’est en devenant admin et étant confronté à des codes/requêtes testé(e)s sur de petits cas de tests mais qui se révélaient désastreux sur un cas réel (genre testé en 0.1s avec une table à 100 éléments, et qui prends 8h sur une table avec 10000). Le tout sur des serveurs plutôt “costaux”.
Et là le langage (haut niveau) n’y était pour rien, on aurait pu faire le même en C que ça aurait pris aussi 8h (aller, 7h45, toujours aussi insupportable pour un utilisateur et l’administrateur du pauvre serveur).
Non, la performance vient en premier lieu des algorithmes, pas du code. Mieux vaut un bon algo avec un langage lent qu’un mauvais avec de l’assembleur bien codé mais un algo mal pensé.
Or si on y pense, un outil de supervision a besoin de deux choses :
Le reste, ce sont des problèmes de haut niveau.
Si on refait la même chose que Shinken mais en C, on gagnera en performance sans aucun doute. Mais ceci va tout simplement demander un temps astronomique avec les ressources des projets Nagios ou Shinken, et on perdrait en modularité de code (on ne peux architecturer aussi simplement et rapidement un code en C qu’un code en Python, aussi bon codeur que l’on soit).
On peux se dire que plus on se rapproche du système, moins l’importance des algos est importante, un fork() est un fork() après tout. Mais en fait non, la manière dont on fait les appels bas niveau à un impact direct sur les performances. Par exemple, Nagios passe le plus clair de son temps à faire des choses “de la mauvaise manière” :
Ca tombe bien, ceci a été crié depuis 2 ans maintenant, mais les projets Nagios et centreon-engine s’y attellent aujourd’hui. Je leur souhaite bien du courage. Personnellement j’ai préféré faire confiance aux codeurs de Python qui sont sûrement bien plus doués que moi pour gérer ces problèmes bas niveaux de communication inter-process. Ceci permet par exemple de passer plus de temps sur des aspects importants pour la supervision comme les notions d’importances ou de corrélations. Ces dernières ne demandent pas de puissance de calcul particulières, mais résolvent les problèmes de bon nombres d’administrateurs dans la vie de tous les jours, les problèmes de performances étant désormais oublié 🙂
Le fait de disposer d’un coeur développé en Python permet d’installer un serveur Shinken sur une machine Windows. Conseilles tu cette architecture ? Quelles sont les éventuelles limitations ?
Oui, et vous remarquez que j’ai même mis ceci dans le TOP3 des features! Shinken est conçu/testé pour deux environnements : Linux et Windows.
Le Windows sera moins performant, non par ce qu’il est codé avec les pieds, mais bien parce qu’il a des fork() plus lent (le modèle de sécurité est plus évolué sous Windows, et implique donc des calculs bien supérieurs à ce que l’on fait sous Linux). Je n’ai pas de chiffres, mais on peux s’attendre à diviser les perfs par deux sur le lancement des sondes.
Je conseille donc pour les gros parcs d’avoir si possible des pollers en Linux pour prendre la majorité de la charge (test réseaux, tests des agents, etc). Mais un poller sous Windows peut avoir un gros intérêt également :
Si c’est un reactionner, on peux restarter des services à distances, pratique…
Outre les problèmes de performances, il y a quelques limitations :
Le premier est facilement contournable, surtout avec l’arrivée de la commande CLI dans la nouvelle version.
Le second est plus problématique, et il faudra qu’on s’y attelle sérieusement 🙂
Le dernier sera réglé avec l’UI de Shinken.
Quel environnement de développement (IDE, outil de debug, gestionnaire de version, tracking…) utilises tu pour le développement de Shinken?
Comme tout le monde, ce avec quoi j’ai appris à l’école:
Si des lecteurs sont intéressés pour s’investir dans le développement de Shinken. Quels sont les besoins les plus importants ?
Un peu de tout en fait !
Des codeurs qui ont besoin d’un certain besoin ou veulent s’amuser en Python, des webdesigners qui sont tentés par la nouvelle UI qui se lâche dans ce domaine (on n’a pas peur de l’HTML 5 et du CSS3 on va dire 🙂 ), des rédacteurs de tutos sur le wiki, des modérateurs sur le forum, quelqu’un qui envoie un petit “merci” par mail (ça aide énormément à maintenir le rythme!) ou alors tout simplement un admin qui tente de l’installer, remonte un bug où nous dit qu’il est en production.
Toute personne qui veux aider est la bienvenue, il n’y a pas de “partie réservée” dans ce projet, mis à part le choix du nom (débile en général) de version qui est mon petit coin à moi 🙂
En discutant personnellement avec des responsables informatiques, les principales craintes qu’ils énoncent à l’utilisation de Shinken en environnement de production sont la pérennité de l’équipe de développement (et donc indirectement du produit) et le support technique. Comment les rassurer sur ces points ?
Ce sont des considérations justes et logiques. J’aurai la même en tant qu’admin. Pour l’instant la communauté est en train de monter, les tests se multiplient et le nombres de contributeurs augmente. Mais il n’y a pas encore de SSLL qui le proposent en formation ou intégration (ça arrive). J’ai par exemple déposé le nom Shinken à l’internationnal par exemple,si ceci peux démontrer à quel point j’y crois (surtout quand on connaît mon aversion pour les trucs administratifs, et là j’ai été servi..). Donc je pense que Shinken arrivera dans un premier temps par la petite porte, comme l’a fait Nagios avant lui d’ailleurs.
As tu des références d’entreprises utilisant Shinken pour la supervision de leur système d’information ?
Il y a pour ceux où je suis au courant déjà Lectra, société où je travaille (300 serveurs, 7k services), une section de Sogeti sur Bordeaux (12K services), l’hébergeur Sobio (100 serveurs) et un conseil général.
Si d’ailleurs certains l’ont mis en place, nous sommes en phase de recherche de références !
Est il intéressant de déployer Shinken sur des parcs informatiques de petite et moyenne taille ? (question d’Anthony Paradis modo du forum de Monitoring-FR)
Oui pour les petits, car ils sont souvent sous Windows et là c’est tout simplement leur seule solution “libre” de ce calibre à ma connaissance 😉
Pour les moyens qui sont en pleine virtualisation, le module de création automatique des liens de dépendances entre l’hôte et les VM peux être utile par exemple, et montrer un peu à un DSI l’intérêt de ce genre de projet. On peux également le voir comme un “nagios like” et donc utiliser les mêmes arguments (nombreux!) de ce dernier, mis à part l’importance de la communauté de ce dernier (mais il a désormais un avenir incertain sous cette forme, il devient donc plus dur de le “vendre”).
Il offre aussi des simplications importantes dans la configuration de Nagios, donc un bac°5 n’est pas forcément nécessaire pour mettre en place des escalades de notification à 2h et 4h sur une partie du parc par exemple. Cela prends plutôt 5 mins désormais 🙂
Pour finir, comment vois tu Shinken dans 5 ans ce qui est une éternité pour un logiciel informatique ? (question de Romain de Woueb.net)
Comme une solution à part entière, c’est à dire :
Mais même si nous n’atteignons jamais ça, déjà avoir une grosse communauté et savoir que ce projet a aidé bon nombres d’administrateurs dans leur vie de tous les jours et à leur permettre de se consacrer à des tâches plus intéressantes que courir partout car ils n’arrivent pas à trouver l’élément qui a fait tout tomber, ça serait déjà un objectif tout à fait satisfaisant pour moi.
Le reste (passer devant Nagios, contenir Zabbix, convaincre les gourous de la supervision du bien fondé de ma vision, avoir le temps de finir les deux Final Fantasy que j’ai de retards, …) ce n’est que du bonus. Si de plus ça peux devenir mon gagne pain, ça me permettrait à justifier à ma femme tout ce temps où je passe dessus 🙂
Un petit mot pour finir ?
Comme mot de fin, j’aimerai remercier Nicolas pour cette interview ainsi que tous ceux qui ont posés des questions et qui portent un intérêt à ce projet :).
—
Nous arrivons à la fin de cet interview. Encore merci à Jean pour sa disponibilité et aux lecteurs qui ont posés de questions intéressantes qui montrent l’intérêt du public pour cette solution de supervision.
Vous pouvez bien sûr poser des questions complémentaire à Jean en utilisant le formulaire en bas de cette page.
Quelques liens relatifs à Shinken:

Je viens de passer le cap et de m’abonner à un serveur dédié chez Online.net. Mon choix s’est porté vers une Dedibox DC. J’ai longtemps hésité avec une OVH Kimsufi 16G mais le fait que la Dedibox propose en standard deux disques fonctionnant en RAID1 à fait la différence (avec l’âge ou privilégie la sécurité à la performance…).
Avant de migrer mon blog sur ce nouveau serveur (il est actuellement hébergé chez un VPS Gandi 4 parts), j’ai profité de disposer d’un serveur tout neuf pour valider une procédure complète d’installation et d’optimisation d’un blog WordPress sur un serveur Debian Squeeze en utilisant le « stack » Web suivant: Varnish + Nginx + MemCached.
L’objectif de ce billet est de partager cette procédure avec vous.
Nous allons donc détaillé l’installation d’un blog WordPress sur une installation toute fraîche de Debian Squeeze (version stable) pré-installé dans mon cas par Online.net avec un minimum de logiciels (pas d’Apache ni d’autres serveurs Web). Vous l’avez compris, pour suivre la procédure suivante, il faut s’assurer qu’aucun serveur Web n’est installé sur votre machine.
J’ai pris l’habitude de créer des scripts de post installation pour les OS (desktop et server) que j’utilise. Dans le cas qui nous intéresse je vais donc utiliser le script: squeezeserverpostinstall.sh.
Pour le télécharger puis le lancer, il suffit de saisir les commandes suivantes à partir d’un compte administrateur ou directement en root):
wget --no-check-certificate https://raw.github.com/nicolargo/debianpostinstall/master/squeezeserverpostinstall.sh chmod a+x squeezeserverpostinstall.sh ./squeezeserverpostinstall.sh
Comme le serveur est directement connecté à Internet et à moins d’être très joueur, je vous conseille de configurer quelques règles de Firewall. J’ai mis à disposition un jeu de règles assez facile à modifier en éditant le fichier /etc/init.d/firewall.sh. Pour le télécharger et l’installer:
wget --no-check-certificate -O /etc/init.d/firewall.sh https://raw.github.com/nicolargo/debianpostinstall/master/firewall.sh chmod a+x /etc/init.d/firewall.sh update-rc.d firewall.sh defaults 20 service firewall start
Note: par défaut les ports SSH entrant et HTTP et DNS sortant sont autorisés.
Pour modifier ces listes, il suffit de configurer les variables suivantes dans le fichier /etc/init.d/firewall.sh:
# Services that the system will offer to the network TCP_SERVICES="22" # SSH only UDP_SERVICES="" # Services the system will use from the network REMOTE_TCP_SERVICES="80 443" # web browsing REMOTE_UDP_SERVICES="53" # DNS
A ce stade, vous devriez avoir un serveur à jour et sécurisé. Passons donc à l’étape suivante.
C’est actuellement une des combos les plus performantes pour héberger des serveurs Web basées sur PHP (ce qui est le cas du CMS WordPress). Pour effectuer simplement et rapidement ces logiciels, j’utilise un script maison: nginxautoinstall.sh. Il faut donc saisir les commandes suivantes:
wget --no-check-certificate https://raw.github.com/nicolargo/debianpostinstall/master/nginxautoinstall.sh chmod a+x nginxautoinstall.sh ./nginxautoinstall.sh
Le script va installer la dernière version stable de Nginx puis le daemon PHP-FPM qui permet de booster les performances des scripts PHP et enfin le gestionnaire de cache mémoire MemCached (note: le script fonctionne également sur Debian Lenny 5).
Pour adapter les performances de Nginx à votre CPU, il faut modifier la variable worker_processes le fichier /etc/nginx/nginx.conf. Pour obtenir la valeur optimale pour votre système, vous pouvez lancer la commande suivante:
cat /proc/cpuinfo | grep processor | wc -l
Qui donne la valeur 4 sur ma Dedibox (4 coeurs/CPU). On édite le fichier nginx.conf de la manière suivante:
user www-data;
# Set this value to 1 or N with N = N-Core
worker_processes 4;
worker_rlimit_nofile 8192;
events {
# max_clients = worker_processes * worker_connections
worker_connections 1024;
# Only for Linux 2.6 or >
use epoll;
# Accept as many connections as possible
multi_accept on;
}
http {
# Mime types
include mime.types;
default_type application/octet-stream;
# Log format
set_real_ip_from 127.0.0.1;
real_ip_header X-Forwarded-For;
log_format main '$remote_addr - $remote_user [$time_local] $status '
'"$request" $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
# Hide the Nginx version number
server_tokens off;
# Some tweeks...
sendfile on;
tcp_nodelay on;
#tcp_nopush on;
# Timeouts
#keepalive_timeout 10 10;
keepalive_timeout 65;
client_body_timeout 30;
client_header_timeout 30;
send_timeout 30;
client_max_body_size 8M;
reset_timedout_connection on;
# Gzip module configuration
gzip on;
gzip_disable "MSIE [1-6].(?!.*SV1)";
gzip_vary on;
gzip_comp_level 3;
gzip_proxied any;
gzip_buffers 16 8k;
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
}
On relance le serveur pour prendre en compte la configuration:
service nginx restart
WordPress use et abuse du langage PHP, une installation optimisé du moteur permettant d’exécuter le code est donc nécessaire. Personnellement j’utilise l’implémentation PHP5 FPM qui est réputé pour ses performances. Elle est installé par défaut avec mon script d’auto-install de Nginx.
La configuration est stocké dans le répertoire /etc/php5/fpm. Mon fichier php-fpm.conf ressemble à cela:
[global] pid = /var/run/php5-fpm.pid error_log = /var/log/php5-fpm.log emergency_restart_interval = 1m process_control_timeout = 10s include=/etc/php5/fpm/pool.d/*.conf
Avec WordPress comme CMS, je vous encourage à stocker les fichiers de sessions dans une base NoSQL de type Redis afin de ne pas se retrouver avec des milliers de petits fichiers dans le répertoire /tmp. Pour cela, il suffit d’ajouter les lignes suivantes dans le fichier /etc/php5/fpm/php.ini:
session.save_handler = "redis" session.save_path = "tcp://127.0.0.1:6379?weight=1"
Dernière étape et non des moindres, la configuration du pool de processus PHP-FPM que vous allez dédier à votre blog WordPress (par exemple /etc/php5/fpm/pool.d/www.conf dans mon cas):
[www] user = www-data group = www-data listen = 127.0.0.1:9000 pm = dynamic pm.max_children = 5 pm.start_servers = 2 pm.min_spare_servers = 1 pm.max_spare_servers = 3 pm.status_path = /status request_terminate_timeout = 120s rlimit_files = 65535 chdir = /
On peut relancer PHP
service php5-fpm restart
et passer à l’étape suivante, la base de donnée…
A l’heure actuelle, WordPress utilise une base de donnée MySQL pour fonctionner (je préférerai PgSQL mais bon…). Il faut donc installer le serveur de base de donnée MySQL:
apt-get install mysql-server php5-mysql service php5-fpm restart
Optimiser un peu celle-ci en modifiant quelques variables dans le fichier /etc/mysql/my.cnf:
query_cache_type = 1 query_cache_limit = 2M query_cache_size = 32M
et relancer le daemon pour que la configuration soit prise en compte:
service mysql restart
On passe ensuite à la phase de création de la base de données nommée wordpress accessible par utilisateur/motdepasse:
# mysql -u root -p mysql> create database wordpress; Query OK, 1 row affected (0.00 sec) mysql> GRANT ALL PRIVILEGES ON wordpress.* TO "utilisateur"@"localhost" IDENTIFIED BY "motdepasse"; Query OK, 0 rows affected (0.00 sec) mysql> FLUSH PRIVILEGES; Query OK, 0 rows affected (0.00 sec) mysql> exit
J’utilise la dernière version stable de WordPress disponible sur le site officiel:
cd /var/www wget http://wordpress.org/latest.tar.gz tar zxvf latest.tar.gz cp wordpress/wp-config-sample.php wordpress/wp-config.php chown -R www-data:www-data /var/www/wordpress
Ensuite on configure la base de donnée dans le fichier wordpress/wp-config.php:
...
define('DB_NAME', 'wordpress');
define('DB_USER', 'utilisateur');
define('DB_PASSWORD', 'motdepasse');
define('WP_CACHE', true);
...
Il suffit ensuite de finaliser l’installation de WordPress en pointant un navigateur Web vers http://votredomaine.com/wordpress/wp-admin/install.php.
server{
listen 80;
server_name blog.nicolargo.com;
root /var/www/blog.nicolargo.com;
index index.php index.html index.htm;
access_log /var/log/nginx/blog.access_log;
error_log /var/log/nginx/blog.error_log;
# Security
include global/security.conf;
location / {
# This is cool because no php is touched for static content.
# include the "?$args" part so non-default permalinks doesn't break
when using query string
try_files $uri $uri/ /index.php?$args;
}
# PHP-FPM
include global/php-fpm.conf;
# STATICS FILES
location ~* \.(js|css|png|jpg|jpeg|gif|ico)$ {
expires max;
log_not_found off;
}
}
avec les fichiers inclus suivants:
Securité /etc/nginx/global/security.conf:
location = /favicon.ico {
log_not_found off;
access_log off;
}
location = /robots.txt {
allow all;
log_not_found off;
access_log off;
}
location ~ /\. {
deny all;
access_log off;
log_not_found off;
}
et PHP-FPM /etc/nginx/global/php-fpm.conf:
# PHP scripts -> PHP-FPM server listening on 127.0.0.1:9000
location ~ \.php$ {
# The following line prevents malicious php code to be executed through some uploaded file (without php extension, like image)
# This fix shoudn't work though, if nginx and php are not on the same server, other options exist (like unauthorizing php execution within upload folder)
# More on this serious security concern in the "Pass Non-PHP Requests to PHP" section, there http://wiki.nginx.org/Pitfalls
try_files $uri =404;
# PHP
# NOTE: You should have "cgi.fix_pathinfo = 0;" in php.ini
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
fastcgi_param QUERY_STRING $query_string;
fastcgi_param REQUEST_METHOD $request_method;
fastcgi_param CONTENT_TYPE $content_type;
fastcgi_param CONTENT_LENGTH $content_length;
fastcgi_intercept_errors on;
fastcgi_ignore_client_abort off;
fastcgi_connect_timeout 60;
fastcgi_send_timeout 180;
fastcgi_read_timeout 180;
fastcgi_buffers 4 256k;
fastcgi_buffer_size 128k;
#fastcgi_buffers 256 16k;
#fastcgi_buffer_size 16k;
fastcgi_busy_buffers_size 256k;
fastcgi_temp_file_write_size 256k;
}
Ne pas oublier de relancer NGinx pour prendre en compte cette modification:
service nginx restart
Après quelques années sous d’utilisation de W3 Total Cache et la mise en place de mon proxy/cache Varnish, j’ai choisi d’utiliser le plugin WP Super Cache qui s’occupe de cacher les pages demandées par les utilisateurs non identifiées (donc pas 90% du trafic) afin que PHP et MySQL ne soit pas appelé lors de ces requêtes.
Il est également possible de précharger la mise en cache des pages les plus visitées et de les mettre automatiquement à jour de manière régulière.
Une fois installé et activé il faut se rendre dans le menu de configuration du plugin et de cliquer sur l’onglet « Easy » et « Mise en cache Activée (Recommandé) ».
A ce stade, on peut faire quelques tests de performances avec Apache Bench (disponible dans le paquet Debian apache2-utils):
[cce lang= »bash »]
Requests per second: 219.53 [#/sec] (mean) (options -t 30 -c 5)
[/cce]
ou avec le service en ligne Load Impact qui permet de simuler gratuitement jusqu’à 50 utilisateurs simultanés sur votre site:

On voit bien que les page du blog se chargent rapidement (environ 500ms) même avec 50 utilisateurs simultanés.
J’ai mis à jour ma configuration de Varnish+Nginx pour WordPress dans le billet suivant. Vous pouvez le suivre en lieu et place du chapitre qui suit…
Vous savez tout le bien que je pense de Varnish. Nous allons donc maintenant ajouter cet accélérateur de site Web dans notre configuration. Il est à noter que cette étape est optionnelle. Vous pouvez tout à fait rester avec la configuration du chapitre précédent qui offre déjà de belles performances.
On commence par installer la dernière version de Varnish en utilisant le dépôt officiel.
apt-get install curl curl http://repo.varnish-cache.org/debian/GPG-key.txt | apt-key add - echo "deb http://repo.varnish-cache.org/debian/ $(lsb_release -s -c) varnish-3.0" >> /etc/apt/sources.list.d/varnish.list apt-get update apt-get install varnish
La version 3 de Varnish apporte certaines modifications au niveau de la syntaxe des fichiers de configuration. Si vous avez donc une config fonctionnelle en version 2, je vous conseille de lire cette page pour l’adapter.
On commence par éditer le fichier de configuration /etc/varnish/default.vcl:
Puis la manière dont le daemon va se lancer dans le fichier /etc/default/varnish:
Enfin on reconfigure NGinx pour ne plus écouter sur le port 80 (c’est Varnish qui va prendre le relais) mais sur le port 8080. Il suffit de changer la deuxième ligne du fichier /etc/nginx/sites-enabled/wordpress:
... listen 8080; ...
On n’oublie pas d’ouvrir les port au niveau du Firewall (fichier /etc/init.d/firewall.sh):
# Services that the system will offer to the network TCP_SERVICES="22 80" # SSH, Web UDP_SERVICES="" # Services the system will use from the network REMOTE_TCP_SERVICES="25 80 443" # Mail, Web browsing REMOTE_UDP_SERVICES="53" # DNS ...
On relance les services:
service firewall.sh restart service nginx restart service varnish restart
Afin pour que Varnish soit prévenu quand un billet est modifié, il faut installer et activier le plugin Varnish HTTP purge.
Le site devrait fonctionner normalement mais avec des performances boostées. Par exemple, le même test Apache Bench donne les résultats suivants:
Requests per second: 9425.03 [#/sec] (mean) (options -t 30 -c 5)
A comparer avec 220 requêtes par secondes sans Varnish…
On voit même une amélioration du temps de chargement des pages (300ms vs 500ms) qui reste constant avec Load Impact:

On arrive à la fin de ce (trop ?) long billet. Le sujet est vaste et il y a sûrement des améliorations à faire dans la configuration que je viens de vous présenter. Les commentaires ci-dessous sont fait pour partager vos expériences.
Je vous signale également que je regroupe tout les billets sur l’hébergement sur la page suivante.